
Webアプリケーション開発においてレイヤードアーキテクチャは広く採用されていますが、Rustで同じ設計を適用しようとすると、所有権やライフタイムといった言語固有の制約に直面します。「Rustとレイヤードアーキテクチャは相性がよいのか」という疑問は、Rustでの本格的なアプリケーション開発を検討する多くのエンジニアが抱える課題です。
結論として、Rustとレイヤードアーキテクチャの相性は良好です。ただし、JavaやGoと同じ感覚で実装するとコンパイルエラーに阻まれます。Rust固有の仕組みを理解した上で設計すれば、型安全性とレイヤー分離の両方を高いレベルで実現できます。
レイヤードアーキテクチャの基本構造
レイヤードアーキテクチャは、アプリケーションを責務ごとに水平な層(レイヤー)に分割する設計手法です。一般的な4層構成は以下のとおりです。
| 層 | 責務 | Rustでの実装単位 |
|---|---|---|
| プレゼンテーション層 | HTTPリクエスト/レスポンス処理 | axumのHandler・Router |
| アプリケーション層 | ユースケースの実行、トランザクション管理 | サービス構造体 |
| ドメイン層 | ビジネスルール、エンティティ、値オブジェクト | 構造体 + impl |
| インフラストラクチャ層 | DB接続、外部API呼び出し | トレイト実装体 |
各層は上位から下位への一方向の依存関係を持ち、ドメイン層は他のどの層にも依存しません。この原則により、ビジネスロジックがフレームワークやDBの実装詳細から分離されます。
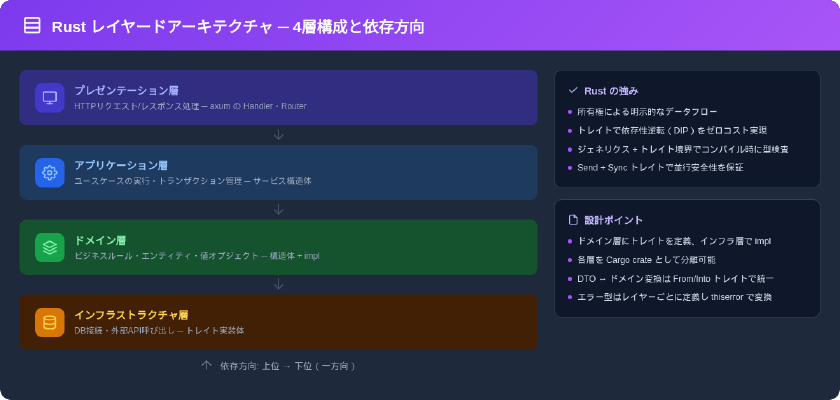
Rustの言語特性がレイヤード設計と噛み合うポイント
所有権システムによるデータフローの明示化
Rustの所有権(ownership)は、レイヤー間のデータ受け渡しを明示的にします。JavaやGoではオブジェクト参照が暗黙的にコピーされますが、Rustでは値の移動(move)が基本です。
// アプリケーション層からドメイン層への値の移動
fn create_user(input: CreateUserInput) -> Result<User, DomainError> {
// inputの所有権はこの関数に移動している
let name = UserName::new(input.name)?; // input.nameの所有権が移動
let email = Email::new(input.email)?; // input.emailの所有権が移動
Ok(User::new(name, email))
}
レイヤー間でデータがどの方向に流れ、どこで消費されるかがコンパイル時に保証されます。これは設計上のミス(意図しないデータ共有や変更)を防ぐ効果があります。
トレイトによる依存性逆転(DIP)
レイヤードアーキテクチャでは、上位層が下位層の具体的な実装に依存しないことが重要です。Rustではトレイト(trait)を使ってこの依存性逆転の原則(Dependency Inversion Principle)を自然に実現できます。
// ドメイン層でリポジトリのインターフェースを定義
#[async_trait]
pub trait UserRepository: Send + Sync {
async fn find_by_id(&self, id: &UserId) -> Result<Option<User>, RepositoryError>;
async fn save(&self, user: &User) -> Result<(), RepositoryError>;
}
// アプリケーション層はトレイトに依存(具体実装には依存しない)
pub struct UserService<R: UserRepository> {
repository: R,
}
impl<R: UserRepository> UserService<R> {
pub fn new(repository: R) -> Self {
Self { repository }
}
pub async fn get_user(&self, id: &UserId) -> Result<Option<User>, AppError> {
self.repository
.find_by_id(id)
.await
.map_err(AppError::from)
}
}
ジェネリクスとトレイト境界を組み合わせることで、コンパイル時に型チェックが行われ、実行時のオーバーヘッドなしにDIPを実現できます。JavaのインターフェースやGoのインターフェースと異なり、Rustのトレイトはゼロコスト抽象化として機能します。
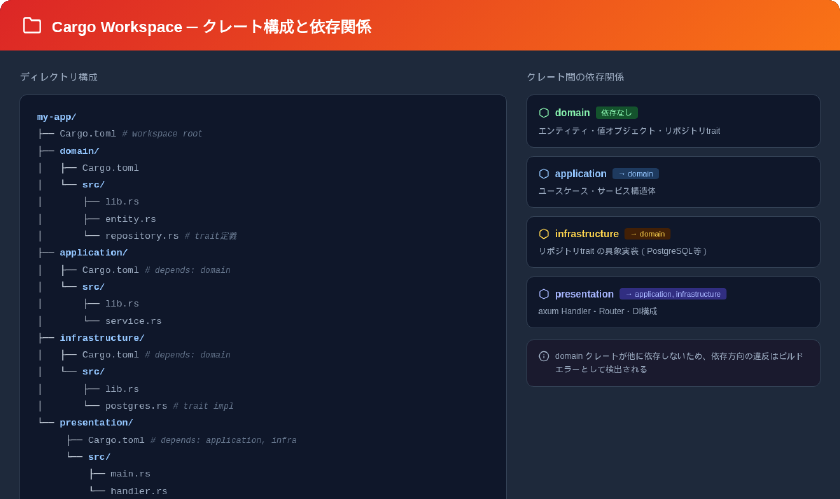
モジュールシステムとCargo workspaceによるレイヤー分離
Rustのモジュールシステムはレイヤーの分離を物理的に強制できます。特にCargo workspaceを使ったマルチクレート構成が有効です。
ワークスペースのルート Cargo.toml は以下のように記述します。
[workspace]
members = ["domain", "application", "infrastructure", "presentation"]
resolver = "2"
各クレートの Cargo.toml で依存関係を明示することで、層の依存方向がビルドシステムレベルで強制されます。ドメインクレートがインフラストラクチャクレートに依存しようとすると、そもそも Cargo.toml に書かれていないためコンパイルエラーになります。
この仕組みはJavaのマルチモジュール(Gradle/Maven)やGoのパッケージ構成よりも厳格です。ビルドツールが依存方向の違反を即座に検出するため、アーキテクチャの腐敗を物理的に防止できます。
Rustでレイヤードアーキテクチャを採用する際の課題と対処法
課題1: 所有権とライフタイムの壁
レイヤー間でデータを受け渡す際、参照(&T)を使うとライフタイムの制約が伝播し、コードが複雑になることがあります。
対処法: 各層でDTOを分離し、値の移動(move)を基本にする
// プレゼンテーション層のリクエスト型
#[derive(Deserialize)]
pub struct CreateUserRequest {
pub name: String,
pub email: String,
}
// アプリケーション層のコマンド型
pub struct CreateUserCommand {
pub name: String,
pub email: String,
}
// 変換はFromトレイトで実装
impl From<CreateUserRequest> for CreateUserCommand {
fn from(req: CreateUserRequest) -> Self {
Self {
name: req.name,
email: req.email,
}
}
}
各層に専用の型を用意し、From / Into トレイトで変換するパターンが定番です。ライフタイム注釈は不要になり、レイヤー間の結合度も下がります。Clone を回避し move を基本とすることで、パフォーマンスへの影響も最小限に抑えられます。
課題2: async traitの取り扱い
リポジトリのメソッドは非同期(async)にしたいケースが多いですが、Rustのトレイトで非同期メソッドを扱うには工夫が必要です。
Rust 1.75以降ではRPIT(Return Position Impl Trait)in traitが安定化されましたが、dyn Traitでの使用にはまだ制約があります。実用上は async-trait クレートの利用が一般的です。
use async_trait::async_trait;
#[async_trait]
pub trait OrderRepository: Send + Sync {
async fn find_by_id(&self, id: &OrderId) -> Result<Option<Order>, RepositoryError>;
async fn save(&self, order: &Order) -> Result<(), RepositoryError>;
async fn delete(&self, id: &OrderId) -> Result<(), RepositoryError>;
}
async-trait は内部的に Pin<Box<dyn Future>> に変換するため、ヒープアロケーションが発生します。ただし、DB I/Oやネットワーク通信の待ち時間と比較すれば、このオーバーヘッドは実測上ほぼ無視できます。
課題3: エラー型の設計
レイヤードアーキテクチャでは各層のエラーをどう統合するかが設計課題です。Rustでは thiserror と anyhow の使い分けが重要になります。
// ドメイン層: 具体的なエラー型を定義
#[derive(Debug, thiserror::Error)]
pub enum DomainError {
#[error("ユーザー名は1〜50文字で入力してください")]
InvalidUserName,
#[error("メールアドレスの形式が不正です")]
InvalidEmail,
}
// アプリケーション層: ドメインエラーをラップ
#[derive(Debug, thiserror::Error)]
pub enum AppError {
#[error(transparent)]
Domain(#[from] DomainError),
#[error(transparent)]
Repository(#[from] RepositoryError),
#[error("ユーザーが見つかりません: {0}")]
UserNotFound(String),
}
// プレゼンテーション層: HTTPステータスコードへ変換
impl IntoResponse for AppError {
fn into_response(self) -> Response {
let (status, message) = match &self {
AppError::Domain(_) => (StatusCode::BAD_REQUEST, self.to_string()),
AppError::UserNotFound(_) => (StatusCode::NOT_FOUND, self.to_string()),
AppError::Repository(_) => (
StatusCode::INTERNAL_SERVER_ERROR,
"内部エラーが発生しました".to_string(),
),
};
(status, Json(json!({ "error": message }))).into_response()
}
}
設計指針: ドメイン層とアプリケーション層では thiserror で明示的なエラー型を定義し、インフラストラクチャ層の内部実装でのみ anyhow を使う方法が実用的です。これにより、上位層ではパターンマッチで適切にエラーを分岐できます。
課題4: DI(依存性注入)の組み立て
Javaの Spring やGoの wire のようなDIコンテナはRustには標準的なものがありません。Rustではコンストラクタインジェクション(手動DI)が主流です。
// main.rsでの組み立て例
#[tokio::main]
async fn main() {
let pool = PgPool::connect("postgres://localhost/mydb")
.await
.expect("DB接続に失敗");
// インフラ層の具体実装を生成
let user_repo = PgUserRepository::new(pool.clone());
let order_repo = PgOrderRepository::new(pool.clone());
// アプリケーション層にインフラ層の実装を注入
let user_service = UserService::new(user_repo);
let order_service = OrderService::new(order_repo);
// プレゼンテーション層(axumのRouter)にサービスを登録
let app = Router::new()
.route("/users/:id", get(get_user))
.route("/users", post(create_user))
.with_state(AppState {
user_service: Arc::new(user_service),
order_service: Arc::new(order_service),
});
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000")
.await
.unwrap();
axum::serve(listener, app).await.unwrap();
}
DIコンテナがない分、依存関係がすべてコンパイル時に解決されます。アプリケーションの起動時に「何が何に依存しているか」が main.rs を読むだけで把握できるのは、大規模プロジェクトでの保守性において利点です。
他言語との比較: レイヤードアーキテクチャの実装しやすさ
| 観点 | Rust | Java (Spring) | Go | TypeScript (NestJS) |
|---|---|---|---|---|
| 依存性逆転 | trait + ジェネリクス(ゼロコスト) | interface + DI Container | interface(暗黙的) | abstract class / interface + DI Container |
| レイヤー分離の強制 | Cargo workspace(ビルドレベル) | マルチモジュール(Gradle/Maven) | パッケージ構成(規約ベース) | モジュールシステム(規約ベース) |
| DI方式 | 手動コンストラクタ注入 | アノテーション自動注入 | 手動 or wire | デコレータ自動注入 |
| エラーハンドリング | Result型(コンパイル時強制) | 例外(実行時) | error値(慣習ベース) | 例外(実行時) |
| テスト時のモック | mockallクレート等 | Mockito等 | 手動実装 or gomock | jest.mock等 |
| 学習コスト | 高(所有権・ライフタイム) | 中(DI設定の理解) | 低 | 中(デコレータの理解) |
| 型安全性 | 非常に高い | 高い | 中程度 | 高い(strict mode時) |
Rustはレイヤードアーキテクチャの実装において「学習コストが高い代わりに、型安全性とパフォーマンスの両方で最も高い水準を実現できる」というポジションにあります。
axum + Cargo workspaceでの実装例
実際にaxumフレームワークとCargo workspaceを使って、レイヤードアーキテクチャのプロジェクトを構成する手順を示します。
ステップ1: ワークスペースの作成
mkdir my-layered-app && cd my-layered-app
cargo init --name presentation
cargo init --lib --name domain domain
cargo init --lib --name application application
cargo init --lib --name infrastructure infrastructure
ステップ2: ドメイン層の実装
ドメイン層は外部クレートへの依存を最小限にします。
// domain/src/lib.rs
pub mod model;
pub mod repository;
pub mod error;
// domain/src/model/user.rs
#[derive(Debug, Clone)]
pub struct User {
id: UserId,
name: UserName,
email: Email,
}
#[derive(Debug, Clone, PartialEq)]
pub struct UserId(String);
#[derive(Debug, Clone)]
pub struct UserName(String);
impl UserName {
pub fn new(value: String) -> Result<Self, DomainError> {
if value.is_empty() || value.len() > 50 {
return Err(DomainError::InvalidUserName);
}
Ok(Self(value))
}
pub fn value(&self) -> &str {
&self.0
}
}
値オブジェクト(UserId, UserName)をnewtypeパターンで定義し、生成時にバリデーションを行います。プリミティブ型(String)を直接使わないことで、層をまたいだ不正な値の流入を型レベルで防止できます。
ステップ3: アプリケーション層の実装
// application/src/usecase/create_user.rs
use domain::model::user::{User, UserName, Email};
use domain::repository::UserRepository;
use domain::error::DomainError;
pub struct CreateUserUseCase<R: UserRepository> {
user_repository: R,
}
impl<R: UserRepository> CreateUserUseCase<R> {
pub fn new(user_repository: R) -> Self {
Self { user_repository }
}
pub async fn execute(&self, input: CreateUserInput) -> Result<User, AppError> {
let name = UserName::new(input.name)?;
let email = Email::new(input.email)?;
let user = User::new(name, email);
self.user_repository.save(&user).await?;
Ok(user)
}
}
pub struct CreateUserInput {
pub name: String,
pub email: String,
}
ステップ4: テスト戦略
レイヤードアーキテクチャの最大の利点の一つが、レイヤーごとの独立したテストです。Rustでは mockall クレートを使ってリポジトリのモックを生成できます。
#[cfg(test)]
mod tests {
use super::*;
use domain::repository::MockUserRepository;
#[tokio::test]
async fn ユーザーを正常に作成できる() {
let mut mock_repo = MockUserRepository::new();
mock_repo
.expect_save()
.times(1)
.returning(|_| Ok(()));
let usecase = CreateUserUseCase::new(mock_repo);
let input = CreateUserInput {
name: "田中太郎".to_string(),
email: "tanaka@example.com".to_string(),
};
let result = usecase.execute(input).await;
assert!(result.is_ok());
}
#[tokio::test]
async fn 空のユーザー名はエラーになる() {
let mock_repo = MockUserRepository::new();
let usecase = CreateUserUseCase::new(mock_repo);
let input = CreateUserInput {
name: "".to_string(),
email: "test@example.com".to_string(),
};
let result = usecase.execute(input).await;
assert!(matches!(
result,
Err(AppError::Domain(DomainError::InvalidUserName))
));
}
}
ドメイン層の単体テストにはモックすら不要です。純粋な関数とデータ構造のテストだけで済むため、テストの実行速度が非常に速くなります。
レイヤードアーキテクチャとオニオン/クリーンアーキテクチャの使い分け
Rustプロジェクトで「レイヤードアーキテクチャ」と混同されやすいのが、オニオンアーキテクチャやクリーンアーキテクチャです。
| 設計手法 | 依存方向 | Rustとの相性 | 適用規模の目安 |
|---|---|---|---|
| レイヤードアーキテクチャ | 上→下(一方向) | 高い。Cargo workspaceで自然に表現可能 | 小〜中規模 |
| オニオンアーキテクチャ | 外→内(同心円) | 高い。トレイトでドメイン中心の設計が実現しやすい | 中〜大規模 |
| クリーンアーキテクチャ | 外→内 + ユースケース中心 | 高いが層数が増え、型変換のボイラープレートも増加 | 大規模 |
実際のRustプロジェクトでは、レイヤードアーキテクチャをベースに依存性逆転を取り入れた「オニオン寄りのレイヤード」が採用されるケースが多くあります。ドメイン層にリポジトリのトレイトを定義し、インフラ層で実装するパターンは、純粋なレイヤードというよりもオニオンアーキテクチャの要素を含んでいます。
小規模なプロジェクトではレイヤードの単純さが利点になり、規模が大きくなるにつれてクリーンアーキテクチャへ段階的に移行する戦略が現実的です。
実プロジェクトで役立つクレート構成
レイヤードアーキテクチャのRustプロジェクトでよく使われるクレートを層別にまとめます。
プレゼンテーション層
| クレート | 用途 |
|---|---|
| axum | Webフレームワーク(tokioベース、型安全なルーティング) |
| tower | ミドルウェアレイヤー(ロギング、認証、レート制限) |
| serde / serde_json | リクエスト・レスポンスのシリアライズ |
| utoipa | OpenAPI仕様の自動生成 |
アプリケーション層
| クレート | 用途 |
|---|---|
| async-trait | トレイトでのasyncメソッド対応 |
| thiserror | エラー型の定義 |
| tracing | 構造化ロギング |
ドメイン層
| クレート | 用途 |
|---|---|
| (原則外部依存なし) | ビジネスロジックの純粋性を保つ |
| derive_more(任意) | newtypeのDisplay等の自動実装 |
インフラストラクチャ層
| クレート | 用途 |
|---|---|
| sqlx | 非同期SQLクエリ(コンパイル時チェック対応) |
| sea-orm | エンティティベースの非同期ORM |
| reqwest | 外部HTTPクライアント |
| redis | Redisクライアント |
sqlxの query! マクロはコンパイル時にSQLの型チェックを行うため、インフラ層のバグをビルド段階で発見できます。これはRust + レイヤードアーキテクチャならではの安全性です。
まとめ
Rustとレイヤードアーキテクチャの相性は良好です。所有権システムがレイヤー間のデータフローを明示化し、トレイトがゼロコストで依存性逆転を実現し、Cargo workspaceがレイヤーの分離をビルドレベルで強制します。
一方で、以下の点はRust固有の考慮事項として押さえておく必要があります。
- 各層にDTO型を用意し、
From/Intoでの変換を基本とする - 非同期トレイトには
async-traitクレートを活用する - エラー型は層ごとに
thiserrorで定義し、Fromで変換チェーンを構築する - DIは手動コンストラクタ注入とし、
main.rsで依存グラフを組み立てる
レイヤードアーキテクチャはJavaやGoの経験があるエンジニアにとって馴染みやすい設計パターンです。Rustに入門する際のアーキテクチャとして採用し、プロジェクトの成長に合わせてオニオンやクリーンアーキテクチャへ発展させていくアプローチが効果的です。