
アーキテクチャ選定が事業成長を左右する理由
ソフトウェアアーキテクチャとは、システムを構成するコンポーネントの配置・通信方式・責務分担を定めた設計上の骨格です。データベース、API、UIなどの要素がどのように連携するかを規定し、システムの拡張性・保守性・可用性を根本から決定します。
アーキテクチャ選定の誤りは、事業に深刻な損害をもたらします。たとえば、月間1,000ユーザーのMVPにマイクロサービスを導入すれば、開発速度が半分以下に落ちてプロダクトマーケットフィット(PMF)の検証が遅れます。逆に、月間500万ユーザーを超えたサービスがモノリスのまま肥大化すると、デプロイに数時間かかり、障害が全機能に波及するリスクを抱えます。
大規模なアーキテクチャの書き直しは、新規開発以上のコストと時間を要するのが一般的です。しかし、最初から「将来を見越した過剰設計」をするのも同様に危険です。重要なのは、いまのサービス規模と次に到達するであろう規模を見据えて、段階的に進化できるアーキテクチャを選ぶことです。
主要アーキテクチャパターンの全体像
サービス設計で選択肢となる主要なアーキテクチャパターンを整理します。各パターンの特性を把握したうえで、自社サービスの規模やフェーズに合った選択をすることが重要です。
モノリス(単一デプロイ型)
すべての機能を1つのアプリケーションとしてビルド・デプロイする構成です。Ruby on Rails、Django、Spring Bootなどのフレームワークで一般的に採用されます。コードベースが1つのため、開発環境のセットアップが容易で、関数呼び出しで処理を完結できるため通信オーバーヘッドがありません。
一方で、コードベースが数十万行を超えるとビルド時間が肥大化し、1つの変更が予期せぬ箇所に波及するリスクが高まります。
モジュラーモノリス
モノリスの内部をドメインごとのモジュールに分割し、モジュール間の依存関係を明示的に管理する構成です。デプロイ単位は1つのままですが、各モジュールが独立した責務を持ち、境界が明確になります。
Shopifyはこの手法を採用しており、280万行を超えるRuby on Railsのコードベースをコンポーネントに分割し、Packwerkというツールでモジュール間の依存違反を検出しています(出典: Shopify Engineering)。
サービスベースアーキテクチャ
アプリケーションを4〜12個程度のサービスに分割する構成です。マイクロサービスほど細かく分割せず、各サービスは比較的大きな粒度のドメインを担当します。サービス間通信はRESTやメッセージキューで行い、データベースは共有する場合もあります。
マイクロサービスへの完全移行が難しい中規模組織にとって、複雑さを抑えつつサービス境界の恩恵を得られる選択肢です。
マイクロサービス
機能単位で独立したサービスに分割し、それぞれが独自のデータストアを持つ構成です。サービスごとに異なるプログラミング言語やフレームワークを採用でき(ポリグロットアーキテクチャ)、チームが独立してデプロイできます。
Netflixは1,000以上のマイクロサービスで構成されており、1日あたり数十億規模のAPIリクエストを処理しています(出典: DevelopersIO)。ただし、分散システム特有の複雑さ(ネットワーク障害、データ整合性、分散トレーシング)が不可避です。
サーバレス
AWS Lambda、Google Cloud Functions、Azure Functionsなどのマネージドサービス上で、関数単位のコードを実行する構成です。インフラ管理が不要で、リクエスト数に応じた従量課金のため、トラフィックが不規則なワークロードに向いています。
ただし、コールドスタートによるレイテンシ増加、実行時間の制限(AWS Lambdaは最大15分)、ベンダーロックインといった制約があります。Amazon Prime Videoの映像品質検査システムでは、サーバレス構成からEC2/ECSベースのモノリス構成に移行した結果、運用コストが90%削減された事例が報告されています(出典: Qiita)。
イベント駆動アーキテクチャ
Apache Kafka、Amazon EventBridge、RabbitMQなどのメッセージブローカーを介して、コンポーネント間が非同期でイベントを発行・購読する構成です。サービス間の疎結合を実現し、高スループットのデータ処理に適しています。リアルタイム分析、IoTデータ収集、決済処理など、大量のイベントを並行処理する場面で威力を発揮します。
他のアーキテクチャパターンと組み合わせて使用するのが一般的で、マイクロサービス間の通信基盤として採用されるケースが多いです。
アーキテクチャパターン比較
| 特性 | モノリス | モジュラーモノリス | サービスベース | マイクロサービス | サーバレス |
|---|---|---|---|---|---|
| デプロイ単位 | 1つ | 1つ | 4〜12 | 数十〜数百 | 関数単位 |
| チーム独立性 | 低い | 中程度 | 中〜高 | 高い | 高い |
| 運用の複雑さ | 低い | 低〜中 | 中程度 | 高い | 中程度(マネージド) |
| スケーリング粒度 | 全体 | 全体 | サービス単位 | サービス単位 | 関数単位 |
| 初期構築コスト | 低い | 低い | 中程度 | 高い | 低〜中 |
| 継続運用コスト(大規模時) | 高い | 中程度 | 中程度 | 中〜高 | 従量課金 |
| 推奨チーム規模 | 1〜15名 | 5〜40名 | 10〜60名 | 30名以上 | 1〜20名 |
サービス規模別アーキテクチャ選定マップ
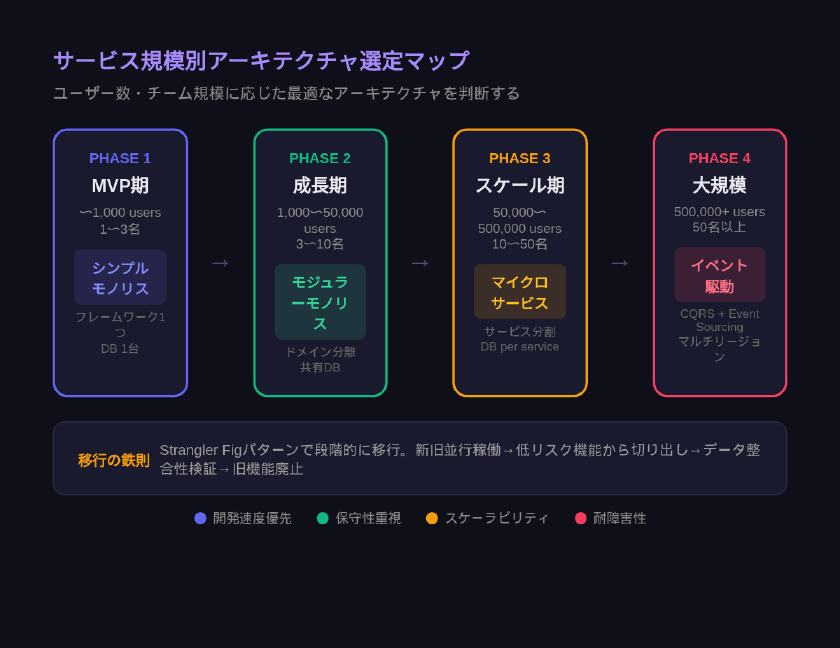
サービスの成長段階ごとに、ユーザー数・チーム人数・トラフィック量の3軸から最適なアーキテクチャを整理します。
ステージ1: MVP・初期プロダクト(ユーザー数 〜1万人)
推奨アーキテクチャ: モノリス
このフェーズの最優先事項は、仮説検証のスピードです。プロダクトの方向性が定まっていない段階で複雑なアーキテクチャを採用すると、ピボット(方向転換)のたびに複数サービスの改修が必要になり、検証サイクルが遅延します。
想定スペック:
- ユーザー数: 数百〜1万人
- 開発チーム: 1〜5名
- 月間リクエスト: 数十万〜数百万
- インフラ月額: 1〜5万円
具体的な構成例:
- アプリケーション: Rails / Django / Next.js など1フレームワーク
- データベース: PostgreSQL または MySQL(マネージドRDS)
- インフラ: AWS EC2(t3.small〜medium)1台、またはCloud Run / ECS Fargate
- キャッシュ: アプリ内メモリキャッシュ、必要に応じてRedis
この段階で意識すべきこと: モノリスであっても、将来の分割を見据えてドメインごとにディレクトリを整理し、モジュール間の依存方向を一方向に保つことが重要です。「認証」「課金」「コアドメイン」の3領域は初期から意識的にコードを分離しておくと、後のモジュラーモノリス化がスムーズになります。
ステージ2: PMF達成後の成長期(ユーザー数 1万〜50万人)
推奨アーキテクチャ: モジュラーモノリス or サービスベース
PMFを達成し、機能追加の速度とシステムの安定性を両立する必要があるフェーズです。開発チームが10名を超えると、モノリス内でのコード衝突やマージコンフリクトが頻発し始めます。
想定スペック:
- ユーザー数: 1万〜50万人
- 開発チーム: 5〜30名
- 月間リクエスト: 数百万〜数千万
- インフラ月額: 5万〜50万円
モジュラーモノリスを選ぶ条件:
- チーム規模が20名以下
- ドメインの境界がまだ流動的
- デプロイパイプラインの複雑化を避けたい
- freeeはこの手法を採用し、数百万行のRailsモノリスをモジュラーモノリスとして再構成しました(出典: 日経XTECH)
サービスベースを選ぶ条件:
- チーム規模が20名以上で、明確な機能領域(決済、検索、通知など)ごとにチームを分割できる
- 特定の機能だけ異なるスケーリングが必要(例: 検索機能のみ高負荷)
- 一部機能で異なる技術スタック(例: 検索にElasticsearch、機械学習にPython)を使いたい
コスト試算例(AWSベース・月額):
| 項目 | 構成 | 概算月額 |
|---|---|---|
| コンピュート | ECS Fargate(2〜4タスク) | 3〜8万円 |
| データベース | RDS PostgreSQL(db.r6g.large) | 4〜6万円 |
| キャッシュ | ElastiCache Redis(cache.r6g.large) | 3〜5万円 |
| ロードバランサー | ALB | 3,000〜5,000円 |
| その他(S3、CloudWatch等) | - | 1〜3万円 |
| 合計 | 12〜25万円 |
※トラフィック量やデータ量で大きく変動します。AWS公式料金計算ツールで正確な見積もりを取得してください。
ステージ3: 急成長・スケール期(ユーザー数 50万〜500万人)
推奨アーキテクチャ: マイクロサービスへの段階的移行
ユーザー数が50万を超えると、単一のデプロイ単位では対処しきれない課題が顕在化します。デプロイ頻度の低下、障害影響範囲の拡大、チーム間の調整コスト増加が典型的な兆候です。
想定スペック:
- ユーザー数: 50万〜500万人
- 開発チーム: 30〜100名
- 月間リクエスト: 数億〜数十億
- インフラ月額: 50万〜500万円
移行の判断指標: 以下の状態が複数当てはまる場合、マイクロサービスへの移行を検討すべきです。
- デプロイ頻度が週1回以下に低下している(DORA指標のEliteチームは1日複数回デプロイ。出典: Google Cloud)
- 1回のデプロイに30分以上かかる
- 特定機能の変更が無関係な機能のテスト失敗を引き起こす
- チーム間のコード変更の衝突が週に複数回発生する
- 特定コンポーネントだけ独立してスケールさせたい
移行すべきでないケース:
- 「マイクロサービスが流行っているから」という理由だけで検討している
- 分散システムの運用経験があるエンジニアがチームにいない
- サービス境界(ドメイン境界)が明確に定義されていない
この段階での参考事例: メルカリは2018年、エンジニア約300名体制でモノリスからマイクロサービスへの移行を開始しました。移行の主目的は、1,000名規模への組織拡大に備えた開発スケーラビリティの確保でした。既存のモノリスと新マイクロサービスを並行稼働させながら、機能単位で段階的に切り出すアプローチを採用しています(出典: Publickey)。
ステージ4: 大規模サービス(ユーザー数 500万人超)
推奨アーキテクチャ: マイクロサービス + イベント駆動
月間数十億リクエストを処理し、数百名規模のエンジニア組織で開発を進めるフェーズです。このレベルでは、サービス間の同期的なAPI呼び出しだけではスループットの限界に達するため、イベント駆動アーキテクチャとの組み合わせが有効です。
想定スペック:
- ユーザー数: 500万人超
- 開発チーム: 100名以上
- 月間リクエスト: 数十億以上
- インフラ月額: 500万円以上
設計上の重要ポイント:
ドメイン単位のサービスグルーピング: Uberは約2,200のマイクロサービスを運用する中で、個々のサービスが乱立する問題に直面し、ドメイン単位でサービスをグルーピングするDOMA(Domain-Oriented Microservice Architecture)を導入しました(出典: Uber Engineering Blog)
非同期メッセージングの導入: Apache KafkaやAmazon SNS/SQSを使った非同期通信により、サービス間の結合度を下げつつ高スループットを実現します
オブザーバビリティへの投資: 分散トレーシング(Jaeger、Datadog APM)、集中ログ管理(Elasticsearch、CloudWatch Logs)、メトリクス収集(Prometheus、Grafana)の3本柱が必須です。LINEでは、多数のマイクロサービスの挙動を追跡するためにZipkinベースの分散トレーシングを導入しています(出典: LINE Engineering)
プラットフォームチームの設置: 個々の開発チームがインフラやCI/CDを独自に構築するのではなく、共通基盤を提供するプラットフォームチームが必要になります
規模別選定の早見表
| フェーズ | ユーザー数 | チーム規模 | 推奨アーキテクチャ | 主な判断理由 |
|---|---|---|---|---|
| MVP | 〜1万 | 1〜5名 | モノリス | 検証速度の最大化 |
| 成長期 | 1万〜50万 | 5〜30名 | モジュラーモノリス / サービスベース | 保守性と開発速度の両立 |
| スケール期 | 50万〜500万 | 30〜100名 | マイクロサービス(段階的) | チーム独立性・個別スケーリング |
| 大規模 | 500万超 | 100名以上 | マイクロサービス + イベント駆動 | 高スループット・組織スケール |
アーキテクチャ選定で考慮すべき5つの評価軸
規模別の目安に加えて、以下の5つの評価軸でアーキテクチャの適合度を判断します。
1. チーム規模と組織構造
コンウェイの法則(「システムの設計は、それを生み出す組織のコミュニケーション構造を反映する」)は、アーキテクチャ選定においても有効です。
- 5名以下: モノリスで全員がコードベース全体を把握できる状態が最も効率的です
- 5〜20名: チーム分割が始まる段階。モジュラーモノリスでモジュールの責務とチームの責務を一致させます
- 20〜50名: サービスベースまたは初期のマイクロサービス。3〜8名のチームが1つのサービスを担当する体制が機能します
- 50名以上: マイクロサービス。チームが独立してデプロイ・運用できる体制が不可欠です
2. ビジネスの変化速度
プロダクトの仕様変更がどの程度の頻度で発生するかによって、アーキテクチャの柔軟性に対する要求が変わります。
- 頻繁にピボットする(スタートアップ初期): モノリスが有利。サービス境界の再定義コストが不要です
- 機能追加が主(成長期): モジュラーモノリスが有利。新機能をモジュールとして追加できます
- 安定運用が主(成熟期): マイクロサービスが有利。個別サービスの独立した改善が可能です
3. 非機能要件(可用性・スケーラビリティ・レイテンシ)
サービスのSLA(Service Level Agreement)やユーザー体験の要件に応じて、アーキテクチャの選択が変わります。
| 非機能要件 | モノリスの対応 | マイクロサービスの対応 |
|---|---|---|
| 可用性99.9%以上 | マルチAZ配置で対応可能 | サービスごとの冗長化が可能 |
| 秒間1万リクエスト以上 | 垂直スケーリングに依存 | 水平スケーリングで個別対応 |
| レイテンシ100ms以下 | プロセス内通信で有利 | ネットワークホップで不利 |
| 部分障害の許容 | 困難(全体に波及) | サーキットブレーカーで対応 |
4. 運用コストとインフラ予算
アーキテクチャが複雑になるほど、インフラ費用だけでなく運用の人件費も増加します。
- モノリス: CI/CDパイプライン1本、監視対象1アプリケーション。運用エンジニア1〜2名で対応可能です
- マイクロサービス(20サービス): CI/CDパイプライン20本、サービスメッシュ、分散トレーシング、集中ログ管理が必要。専任のSRE/プラットフォームチーム(3〜5名)が必要です
- サーバレス: インフラ運用の負担は軽いですが、関数の管理・監視・デバッグのための専用ツールが必要です
AWSの場合、同じ処理量でもアーキテクチャによってコスト構造が異なります。トラフィックが安定している場合はEC2リザーブドインスタンスが最安になり、スパイクが激しい場合はサーバレスやFargateの従量課金が有利です。
5. 技術負債の蓄積リスク
アーキテクチャ選定は、将来の技術負債の蓄積速度にも影響します。
- モノリス: コード量が増えるにつれてモジュール間の暗黙的依存が蓄積しやすいです。「変更するのが怖いコード」が増えていきます
- モジュラーモノリス: 境界が明示されているため、依存関係の監視・制御が可能です。ただし、境界を破るコードが書かれた場合に検知する仕組み(Packwerk、ArchUnit等)が必要です
- マイクロサービス: サービス単位の技術負債は小さく保てますが、サービス間のAPI契約やデータ整合性に関する負債が蓄積します
実際のサービスに学ぶアーキテクチャ選定
国内サービスの規模別事例
メルカリ: モノリスから段階的にマイクロサービスへ
メルカリは2013年のサービス開始時にPHPのモノリスとしてスタートし、急成長にともなってコードベースが肥大化しました。2018年にエンジニア約300名の体制でマイクロサービスへの移行を決断しています。移行の目的は技術的な問題の解決だけでなく、1,000名規模の開発組織に拡大するためのスケーラビリティ確保でした。モノリスと新マイクロサービスを並行稼働させる方式で、機能ごとに段階的な切り出しを進めました(出典: CodeZine)。
freee: モジュラーモノリスとマイクロサービスの併存
会計・人事労務のクラウドサービスを提供するfreeeは、Ruby on Railsで構築された大規模モノリスに対して、2021年からモジュラーモノリスの導入を開始しました。全面的なマイクロサービス化ではなく、認証認可基盤など明確に分離できるドメインだけをマイクロサービスとして切り出す方針を採用しています。モジュラーモノリスとマイクロサービスの併存という現実的なアプローチは、中〜大規模のBtoB SaaSにとって参考になる事例です(出典: 日経XTECH)。
SmartHR: Google Cloudベースのマルチプロダクト基盤
クラウド人事労務ソフトのSmartHRは、Google Cloudのマネージドサービスを活用しています。WebサーバーにはCloud Run、非同期処理にはApp Engineを使い分け、従業員データは数億レコードに達しています。2023年にはプロダクト基盤チームを新設し、マルチプロダクト間のデータ連携基盤を構築しています。プロダクトの成長にあわせてインフラ構成を段階的に進化させてきた事例です(出典: Findy Tools)。
海外サービスの事例
Shopify: 280万行のモジュラーモノリス
ECプラットフォームのShopifyは、10年以上にわたって成長してきたRuby on Railsのモノリスを、マイクロサービスではなくモジュラーモノリスとして再構成しました。280万行を超えるコードベースを「注文」「配送」「在庫」「課金」などのドメインコンポーネントに分割し、Packwerkで依存境界を強制しています。1,000名以上の開発者が1つのコードベースで作業する体制を、モジュラーモノリスで実現している代表例です(出典: Shopify Engineering)。
Netflix: 1,000超のマイクロサービスとイベント駆動
Netflixは1,000以上のマイクロサービスで構成され、190カ国以上にストリーミングサービスを提供しています。各マイクロサービスは独立したチームが開発・運用し、1日に数千回のデプロイを実行しています。ただし、サービス数の増大にともなって全体の見通しが悪くなる課題も公表されており、分散トレーシングや独自のサービスメッシュへの継続的な投資が必要となっています(出典: DevelopersIO)。
Amazon Prime Video: サーバレスからの部分的回帰
Amazon Prime Videoの映像品質検査チームは、AWS Step Functions + Lambdaで構築したサーバレスアーキテクチャを、EC2/ECSベースの構成に移行しました。結果として運用コストが90%削減されています。サーバレスはリクエスト単価が低いものの、大量のデータを連続処理するワークロードではステート管理のオーバーヘッドが大きくなり、EC2での処理が効率的でした。ワークロードの特性に応じてアーキテクチャを使い分ける重要性を示す事例です(出典: Publickey)。
BtoB SaaS(マルチテナント)特有の選定基準
BtoB SaaSでは、複数の企業(テナント)が同一のアプリケーションを共有するマルチテナント構成が一般的です。アーキテクチャ選定において、BtoCとは異なる考慮事項があります。
テナント分離モデルの選択
マルチテナントのデータ分離には大きく3つのモデルがあり、サービス規模によって適切な選択が変わります。
| 分離モデル | 概要 | 適合する規模 | コスト効率 |
|---|---|---|---|
| 共有DB・共有スキーマ | テナントIDカラムで論理分離 | 小〜中規模(〜数百テナント) | 高い |
| 共有DB・個別スキーマ | テナントごとにスキーマ分離 | 中規模(数百〜数千テナント) | 中程度 |
| 個別DB | テナントごとにDB分離 | 大規模 or 高セキュリティ要件 | 低い |
(出典: AWS)
SaaSにおけるアーキテクチャ移行の判断ポイント
BtoB SaaSでは、以下の兆候が出たときにアーキテクチャの見直しを検討します。
- 特定テナントの負荷が他テナントに影響する(ノイジーネイバー問題): テナント単位でのリソース分離が必要です。サービスベースまたはマイクロサービスへの移行を検討します
- テナントごとの機能カスタマイズ要求が増える: フィーチャーフラグとモジュラー設計の組み合わせで対応し、テナント専用のサービスを切り出す判断も視野に入ります
- コンプライアンス要件(データ所在地、暗号化要件)がテナントごとに異なる: データ層の分離やリージョン分散が必要になります
AI・LLMワークロードを考慮した設計
2024年以降、AI機能を組み込んだサービスが急増しています。LLM(大規模言語モデル)のAPIコール、ベクトルデータベース、推論パイプラインなど、AI特有のワークロードはアーキテクチャ選定に新たな視点を加えます。
AIワークロードの特性とアーキテクチャへの影響
| 特性 | 影響 | 対策 |
|---|---|---|
| 高レイテンシ(LLM応答に数秒) | 同期API呼び出しではUX低下 | 非同期処理 + ストリーミング応答 |
| 高コスト(トークン従量課金) | 無制限に呼び出すとコスト爆発 | キャッシュ層、レート制限の設計 |
| GPU依存の推論処理 | 通常のWebサーバーと異なるスケーリング | AI推論をサービスとして分離 |
| 急速な技術変化 | LLMプロバイダーの変更リスク | 抽象化層による切り替え容易性 |
AIワークロードは、サービス全体のアーキテクチャに関わらず独立したサービスとして切り出すのが合理的です。モノリスであっても、AI推論部分だけをAPI化し、非同期で呼び出す構成にすることで、LLMプロバイダーの変更やモデルのアップグレードを本体に影響を与えずに実施できます。
よくある失敗パターンと回避策
失敗1: 時期尚早なマイクロサービス化
MVP段階でマイクロサービスを採用した結果、サービス間通信のデバッグ、分散トランザクション、CI/CDパイプラインの複雑化に開発リソースの大半を奪われ、プロダクト開発が停滞するケースは少なくありません。
回避策: ユーザー数が1万人を超え、チームが10名以上になるまではモノリスで十分です。ただし、将来の分割を見据えたモジュール構造(ドメインごとのディレクトリ分割、明確なインターフェース定義)は初期から導入します。
失敗2: モノリスの無計画な膨張
「動いているから触らない」という姿勢でモノリスを放置した結果、100万行を超えるコードベースに暗黙の依存関係が絡み合い、1行の変更に数日の影響調査が必要になるケースです。
回避策: コードベースが10万行を超えたら、モジュラーモノリスへの移行を計画します。具体的には、以下のステップを踏みます。
- ドメインの境界を特定する(ユーザー管理、課金、コアドメインなど)
- モジュール間の依存関係を可視化する(コード解析ツールの活用)
- 循環依存を解消し、依存の方向を一方向に整理する
- モジュール間の通信をインターフェース経由に制限する
失敗3: 組織構造を無視したアーキテクチャ選定
チーム分割されていない15名の組織でマイクロサービスを導入しても、結局全員が全サービスを触ることになり、分散システムの複雑さだけが増します。逆に、すでに職能横断チームが10個ある組織でモノリスを維持していると、チーム間のコード衝突が開発速度のボトルネックになります。
回避策: アーキテクチャの境界とチームの境界を一致させます。「チームが独立してデプロイできるか」を判断基準にすると、適切なサービス分割の粒度が見えてきます。
失敗4: トレンド追従型の選定
「Netflixがマイクロサービスだから自社も」「サーバレスが流行っているから」という理由でアーキテクチャを選ぶのは、最も避けるべき判断です。Netflixの規模(1,000以上のマイクロサービス、数千名のエンジニア)と自社の規模が一致していなければ、同じ手法は機能しません。
回避策: 「いまの課題は何か」「その課題はアーキテクチャの変更で解決するのか」を明確にしたうえで選定します。デプロイ頻度・リードタイム・障害復旧時間・変更失敗率の4指標(DORA指標)を計測し、定量データに基づいて判断します(出典: Splunk)。
段階的なアーキテクチャ移行の進め方
アーキテクチャの移行は一夜にして完了するものではありません。稼働中のサービスを停止させずに、段階的に新しいアーキテクチャへ移行するアプローチが求められます。
漸進的置換パターン(Strangler Fig Pattern)
マーティン・ファウラーが提唱したストラングラーフィグパターンは、既存システムを一括で置き換えるのではなく、新しいコンポーネントで徐々に包み込みながら移行する手法です(出典: AWS)。
移行のステップ:
- プロキシ層の設置: APIゲートウェイやリバースプロキシを前段に配置し、リクエストのルーティングを制御できるようにします
- 最もリスクの低い機能から着手: ユーザー通知、メール送信、ログ収集など、失敗しても影響が限定的な機能を最初に切り出します
- 新旧システムの並行稼働: 切り出した機能を新サービスで稼働させつつ、問題発生時には旧システムにフォールバックできる体制を維持します
- データ移行と整合性の検証: 新サービスが独自のデータストアを持つ場合、データ同期の仕組みを構築し、整合性を継続的に検証します
- 旧機能の廃止: 新サービスが安定稼働した段階で、旧システムから該当機能を削除します
移行判断の定量的指標
アーキテクチャ移行のタイミングを定量的に判断するためには、以下の指標を継続的に計測します。
| 指標 | 移行検討の閾値 | 計測方法 |
|---|---|---|
| デプロイ頻度 | 週1回以下 | CI/CDツールのデプロイログ |
| デプロイ所要時間 | 30分以上 | CI/CDパイプラインの計測 |
| ビルド時間 | 15分以上 | CI/CDツールの実行ログ |
| テスト実行時間 | 30分以上 | テストランナーの計測 |
| 障害の影響範囲 | 全機能に波及 | インシデントレポート |
| チーム間マージコンフリクト | 週5回以上 | Git統計 |
移行中に守るべき原則
- ビッグバンリプレースを避ける: 全面書き直しは失敗のリスクが極めて高いです。部分的な置換を繰り返す方が安全です
- 移行とビジネス開発を並行する: 移行に全リソースを投入してプロダクト開発が停止する状態は避けます。チームの20〜30%を移行に充てるのが現実的な配分です
- 可逆性を確保する: 移行した機能を元に戻せる仕組み(フィーチャーフラグ、デュアルライト)を設計に組み込みます
- 移行の完了基準を定義する: 「旧システムへのリクエストが全体の1%以下になったら廃止」のように、客観的な完了条件を設定します
まとめ: サービス規模に応じた設計判断の指針
サービスの規模が変われば、最適なアーキテクチャも変わります。ユーザー1万人以下のMVPフェーズではモノリスで検証速度を最大化し、50万人規模の成長期にはモジュラーモノリスやサービスベースで保守性を確保し、500万人を超える大規模フェーズではマイクロサービスとイベント駆動で組織とシステムの両方をスケールさせます。
重要なのは、現在の規模に最適なアーキテクチャを選ぶことと、次の規模へ移行可能な設計余地を残すことの両立です。初期のモノリスでもドメイン境界を意識したモジュール構造を採用し、モジュラーモノリスでは将来のサービス切り出しを見据えたインターフェース設計を行い、マイクロサービスではドメイン単位のグルーピングで管理可能性を保ちます。
アーキテクチャは一度決めたら終わりではなく、サービスの成長とともに進化し続けるものです。定量的な指標を計測し、課題が顕在化した段階で次のステップへ進む判断をすることが、持続的な成長を支える設計の要点です。