
データベースを使ったアプリケーション開発で、レスポンスが遅いと感じたことはないでしょうか。原因の多くは、気づかないうちに膨大な数のSQLクエリが発行されている N+1問題 です。
たとえばユーザー100人の一覧画面で、1回の全件取得+100回の関連テーブル参照、合計 101回 ものクエリが実行されるケースが典型的です。本来2回で済む処理が50倍以上に膨れ上がるため、データ量に比例してアプリケーション全体が劇的に遅くなります。
N+1問題とは何か
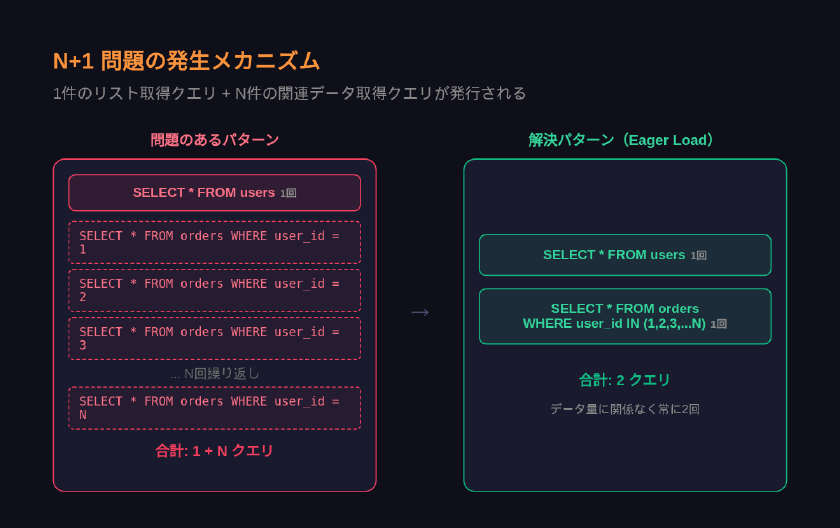
リレーショナルデータベースでは、親テーブルと子テーブルを組み合わせてデータを取得する場面が頻繁にあります。N+1問題は、この関連データの取得時に発生するパフォーマンス上の欠陥です。
具体的な流れは次のとおりです。
- 親テーブルから全レコードを取得する(1回のクエリ)
- 取得した各レコードに対して、子テーブルへ個別にクエリを発行する(N回のクエリ)
合計で N+1回 のクエリが走ります。Nはレコード数なので、データが増えるほどクエリ発行数も線形に増加します。
クエリ発行数はなぜ問題になるのか
クエリ1回ごとにネットワーク往復(ラウンドトリップ)が発生します。アプリケーションサーバーとデータベースサーバーが別マシンの場合、1往復あたり0.5〜2ms程度のオーバーヘッドが加わります。
| レコード数 | N+1時のクエリ数 | JOINで解決した場合 | 差分(倍率) |
|---|---|---|---|
| 10件 | 11回 | 1〜2回 | 約6〜11倍 |
| 100件 | 101回 | 1〜2回 | 約51〜101倍 |
| 1,000件 | 1,001回 | 1〜2回 | 約501〜1,001倍 |
| 10,000件 | 10,001回 | 1〜2回 | 約5,001〜10,001倍 |
ラウンドトリップだけで見ても、レコード1,000件で1秒以上のレイテンシ増が現実的に発生します。さらにデータベース側でもクエリパース・実行計画の策定がクエリ数だけ繰り返されるため、CPU負荷・コネクションプールの圧迫・ロック競合などが連鎖的に起こります。
SQLレベルで見るN+1問題の発生メカニズム
ORMを使わない素のSQLでも、N+1問題の構造を理解しておくと対策が打ちやすくなります。ブログ記事とコメントのテーブルで見てみましょう。
-- テーブル定義
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
body TEXT
);
CREATE TABLE comments (
id SERIAL PRIMARY KEY,
post_id INTEGER REFERENCES posts(id),
content TEXT NOT NULL
);
N+1が発生するクエリパターン
-- 1回目:全記事を取得
SELECT * FROM posts;
-- 記事ごとにコメントを取得(N回)
SELECT * FROM comments WHERE post_id = 1;
SELECT * FROM comments WHERE post_id = 2;
SELECT * FROM comments WHERE post_id = 3;
-- ... post_id = N まで繰り返し
記事が500件あれば、合計501回のクエリが発行されます。
JOINで1回に集約する
SELECT p.id, p.title, c.id AS comment_id, c.content
FROM posts p
LEFT JOIN comments c ON p.id = c.post_id;
これなら1回のクエリで全データを取得できます。ただし、JOINによるデカルト積の肥大化にも注意が必要です(後述の「JOINが逆効果になるケース」で詳しく触れます)。
IN句によるバッチ取得
-- 1回目:全記事を取得
SELECT * FROM posts;
-- 2回目:コメントをまとめて取得
SELECT * FROM comments WHERE post_id IN (1, 2, 3, ..., N);
合計2回のクエリで済みます。ORMのEager Loading機能の多くは、内部でこのIN句パターンを生成しています。
ORM別:N+1問題の発生パターンと対策コード
実際の開発ではORMを通じてデータベースにアクセスするケースがほとんどです。主要なORMごとに、N+1が発生するコードと対策コードを比較します。
Ruby on Rails(ActiveRecord)
N+1が発生するコード:
# コントローラー
@posts = Post.all
# ビュー(各postごとにcommentsへクエリが飛ぶ)
@posts.each do |post|
post.comments.each do |comment|
puts comment.content
end
end
対策:includes / preload / eager_load
# includes: Railsが最適な方法を自動選択
@posts = Post.includes(:comments).all
# preload: IN句で別クエリとして取得(2回)
@posts = Post.preload(:comments).all
# eager_load: LEFT JOINで1クエリに結合
@posts = Post.eager_load(:comments).all
| メソッド | 生成SQL | クエリ数 | 適したケース |
|---|---|---|---|
includes | 状況に応じてIN句またはJOIN | 1〜2回 | 汎用的に使える |
preload | IN句(別クエリ) | 2回 | 子データが多い・多対多の関連 |
eager_load | LEFT OUTER JOIN | 1回 | WHERE句で子テーブルの条件絞り込みが必要 |
Django(Django ORM)
N+1が発生するコード:
# 各blogのauthorにアクセスするたびにクエリが発行される
blogs = Blog.objects.all()
for blog in blogs:
print(blog.author.name)
対策:select_related / prefetch_related
# select_related: JOINで一括取得(ForeignKey/OneToOneField向け)
blogs = Blog.objects.select_related('author').all()
# prefetch_related: IN句で別クエリとして取得(ManyToManyField向け)
blogs = Blog.objects.prefetch_related('tags').all()
| メソッド | リレーション種別 | 内部SQL | クエリ数 |
|---|---|---|---|
select_related | ForeignKey / OneToOne | INNER JOIN | 1回 |
prefetch_related | ManyToMany / 逆参照 | IN句 | 2回 |
Laravel(Eloquent)
N+1が発生するコード:
$posts = Post::all();
foreach ($posts as $post) {
// 毎回クエリが発行される
echo $post->comments->count();
}
対策:with(Eager Loading)
// IN句で関連データを事前に一括取得
$posts = Post::with('comments')->get();
// ネストした関連も指定できる
$posts = Post::with(['comments', 'comments.user'])->get();
// 条件付きEager Loading
$posts = Post::with(['comments' => function ($query) {
$query->where('approved', true);
}])->get();
Go(GORM / sqlx)
Go言語にはRubyやPythonのような暗黙的な遅延ロードがないため、N+1問題は明示的なクエリ設計で発生します。
N+1が発生するコード(GORM):
var users []User
db.Find(&users)
for _, user := range users {
var books []Book
// ユーザーごとに個別クエリ
db.Where("user_id = ?", user.ID).Find(&books)
fmt.Println(user.Name, len(books))
}
対策:Preload / Joins
// Preload: IN句で一括取得
var users []User
db.Preload("Books").Find(&users)
// Joins: JOINクエリを明示的に構築
var users []User
db.Joins("LEFT JOIN books ON books.user_id = users.id").
Select("users.*, COUNT(books.id) as book_count").
Group("users.id").
Find(&users)
対策:sqlxでmap構造を使う方法
// 1回目:ユーザー一覧を取得
rows, _ := db.Query("SELECT id, name FROM users")
var userIDs []int
userMap := make(map[int]User)
for rows.Next() {
var u User
rows.Scan(&u.ID, &u.Name)
userIDs = append(userIDs, u.ID)
userMap[u.ID] = u
}
// 2回目:IN句でまとめて取得
query, args, _ := sqlx.In(
"SELECT * FROM books WHERE user_id IN (?)", userIDs,
)
var books []Book
db.Select(&books, query, args...)
Spring Data JPA(Java / Kotlin)
N+1が発生するコード:
@Entity
public class Company {
@OneToMany(mappedBy = "company", fetch = FetchType.LAZY)
private List<Employee> employees;
}
// companiesを取得した後、employees にアクセスするたびに追加クエリ
List<Company> companies = companyRepository.findAll();
for (Company c : companies) {
System.out.println(c.getEmployees().size()); // ここでN回クエリ
}
対策:JPQL の JOIN FETCH / EntityGraph
// JOIN FETCHを使った方法
@Query("SELECT c FROM Company c LEFT JOIN FETCH c.employees")
List<Company> findAllWithEmployees();
// EntityGraphを使った方法
@EntityGraph(attributePaths = {"employees"})
List<Company> findAll();
| 対策手法 | メリット | デメリット |
|---|---|---|
JOIN FETCH | 1クエリで取得完了 | JPQLの記述が必要 |
@EntityGraph | アノテーションだけで設定可能 | 複雑なグラフでは制御しにくい |
FetchType.EAGER | 設定のみで動作 | 常にJOINされるため不必要な場面でも負荷がかかる |
フレームワーク横断:Eager Loading方式の比較
主要ORMのEager Loading手法を横断的に整理すると、方式の違いが明確になります。
| フレームワーク | JOIN方式 | IN句方式 | 自動選択 | 検出ツール |
|---|---|---|---|---|
| Rails | eager_load | preload | includes | Bullet gem |
| Django | select_related | prefetch_related | なし | django-debug-toolbar |
| Laravel | join() | with() | なし | Laravel Debugbar |
| GORM (Go) | Joins() | Preload() | なし | ログ出力 |
| JPA (Java) | JOIN FETCH | なし(標準) | @EntityGraph | Hibernate Statistics |
N+1問題の検出方法
コードレビューだけでN+1問題を見つけるのは困難です。ツールを活用して、発行されたクエリ数を可視化する方法が効果的です。
Railsでの検出:Bullet gem
# Gemfile
gem 'bullet', group: :development
# config/environments/development.rb
config.after_initialize do
Bullet.enable = true
Bullet.alert = true # ブラウザにアラート表示
Bullet.console = true # ブラウザコンソールに出力
Bullet.rails_logger = true # Railsログに出力
end
Bulletは、N+1クエリを検知すると開発中にアラートを表示します。さらに「不要なEager Loadingの検出」も行うため、過剰な事前読み込みも防止できます。
Djangoでの検出:django-debug-toolbar / nplusone
pip install django-debug-toolbar
# settings.py
INSTALLED_APPS += ['debug_toolbar']
MIDDLEWARE += ['debug_toolbar.middleware.DebugToolbarMiddleware']
INTERNAL_IPS = ['127.0.0.1']
django-debug-toolbarのSQLパネルでは、各リクエストで発行されたクエリの一覧・実行時間・重複クエリが視覚的に確認できます。
nplusoneパッケージを使えば、N+1クエリ発生時に自動で警告を出すことも可能です。
pip install nplusone
INSTALLED_APPS += ['nplusone.ext.django']
MIDDLEWARE += ['nplusone.ext.django.NPlusOneMiddleware']
NPLUSONE_RAISE = True # N+1検出時に例外を発生させる
Laravelでの検出:preventLazyLoading
Laravel 8.43以降では、遅延ロードを完全に禁止する機能が標準で用意されています。
// AppServiceProvider.php
use Illuminate\Database\Eloquent\Model;
public function boot(): void
{
// 開発環境で遅延ロードを禁止(N+1が発生すると例外をスロー)
Model::preventLazyLoading(! app()->isProduction());
}
この設定を有効にすると、with()でEager Loadingしていないリレーションにアクセスした時点でLazyLoadingViolationExceptionがスローされます。N+1問題を開発段階で強制的に検出できる強力な仕組みです。
クエリログによる手動確認
ORMに依存しない汎用的な方法として、データベース側のクエリログを有効にする手段があります。
-- MySQL:一般クエリログを有効化
SET GLOBAL general_log = 'ON';
SET GLOBAL log_output = 'TABLE';
-- ログの確認
SELECT * FROM mysql.general_log
ORDER BY event_time DESC
LIMIT 50;
-- PostgreSQL:postgresql.conf
log_statement = 'all'
log_min_duration_statement = 0
一定時間の操作後にクエリログを集計し、同じテーブルに対するSELECTが数十〜数百回繰り返されていればN+1問題の可能性が高いと判断できます。
JOINが逆効果になるケース
N+1問題の対策として真っ先に挙がるJOINですが、常に最善とは限りません。
多対多リレーションでのデータ膨張
たとえば記事1件にタグが5個、カテゴリが3個付いているとします。JOINですべて結合すると、記事1件あたり 5 × 3 = 15行に展開されます(デカルト積)。記事100件なら1,500行です。
この場合、IN句で関連テーブルを個別に取得する方が転送データ量・メモリ使用量ともに小さくなります。
# Railsの場合:preloadが適切
Post.preload(:tags, :categories)
# eager_loadだとデカルト積が発生して逆効果
Post.eager_load(:tags, :categories)
子レコードが大量にある場合
1件の親レコードに紐づく子レコードが数千件以上ある場合、JOINで全行を取得するとレスポンスサイズが巨大になります。
このようなケースでは、ページネーションと組み合わせるか、必要な集計値だけをサブクエリで取得する方が効率的です。
-- 子レコード数だけが必要な場合
SELECT p.id, p.title, (
SELECT COUNT(*) FROM comments c WHERE c.post_id = p.id
) AS comment_count
FROM posts p;
あえてN+1を許容する場面
すべてのN+1問題を解消すべきとは限りません。以下のようなケースでは、N+1のまま運用した方がコード保守性・キャッシュ効率で有利になることがあります。
- 子テーブルのレコード数が固定的に少ない(都道府県マスタ・ステータスマスタなど)
- アプリケーションキャッシュが効いている(Redisなどでマスタ系データをキャッシュ済みの場合、DBへのクエリ自体が発生しない)
- N(親レコード数)が常に少ない(管理画面の設定項目一覧など、多くても10〜20件程度)
重要なのは「クエリ発行数の把握」です。ツールで実際の発行数を測定したうえで、パフォーマンス要件と照らし合わせて判断するのが正しいアプローチです。
N+1問題を防ぐための設計指針
N+1問題を個別に見つけて修正するだけでなく、設計段階で予防するプラクティスを取り入れることで、根本的な対策になります。
1. デフォルトスコープにEager Loadingを組み込む
よく使う関連データは、モデルのデフォルトスコープでEager Loadingを設定しておくと、取得忘れを防げます。
# Rails
class Post < ApplicationRecord
default_scope { includes(:author) }
end
# Django: Managerをカスタマイズ
class PostManager(models.Manager):
def get_queryset(self):
return super().get_queryset().select_related('author')
class Post(models.Model):
objects = PostManager()
ただし、デフォルトスコープの多用は予期しない挙動を招くことがあります。チームで方針を統一したうえで、必要最小限に留めるのが安全です。
2. API設計でレスポンス構造を意識する
REST APIやGraphQLの設計段階で、1つのエンドポイントが返すデータの深さを決めておくと、N+1の発生箇所を予測しやすくなります。
// NG:ネストが深く、N+1が多段で発生しやすい
{
"posts": [{
"id": 1,
"author": { "name": "...", "profile": { "bio": "..." } },
"comments": [{ "user": { "name": "..." } }]
}]
}
// OK:フラットにして必要なIDだけ返す
{
"posts": [{ "id": 1, "author_id": 10 }],
"authors": [{ "id": 10, "name": "..." }]
}
3. CI/CDでクエリ数を監視する
テスト実行時に発行されたクエリ数を記録し、閾値を超えたらCIを失敗させる仕組みを導入すると、N+1問題がプロダクション環境に到達する前に検知できます。
# RSpec + Bulletの例
RSpec.configure do |config|
config.before(:each) do
Bullet.start_request
end
config.after(:each) do
Bullet.perform_out_of_channel_notifications if Bullet.notification?
Bullet.end_request
end
end
まとめ
N+1問題の本質は、関連データ取得時にレコード数に比例してクエリ発行数が増大する構造的な非効率性にあります。
対策の基本は、各ORMが提供するEager Loading機能(Rails の includes、Django の select_related / prefetch_related、Laravel の with、GORM の Preload、JPA の JOIN FETCH)を適切に使い分けることです。ただし、JOINによるデカルト積の膨張やキャッシュとの相性も考慮して、あえてN+1を許容するケースもあります。
開発プロセスにBulletやdjango-debug-toolbar、preventLazyLoadingなどの検出ツールを組み込み、クエリ発行数を常に把握できる状態を維持することが、パフォーマンス劣化を未然に防ぐ最も確実な方法です。