
クラウド環境でデータを安全かつ効率的に保管・活用するには、ストレージの選定段階から運用を見据えた設計が欠かせません。Google Cloud Storage(GCS)はオブジェクトストレージとしてイレブンナインの耐久性(99.999999999%)と無制限のスケーラビリティを備えていますが、バケット構成やストレージクラスの選択を誤ると、想定外のコスト増やパフォーマンス低下を招きます。
この記事では、要件定義・ストレージ種別の選定・バケット設計・コスト最適化・セキュリティ・AI/MLワークロード対応まで、Cloud Storageの設計プロセスを一気通貫で整理します。
Cloud Storageとは|オブジェクトストレージの基本構造
Cloud Storage(GCS)は、Google Cloudが提供するフルマネージドのオブジェクトストレージサービスです。ファイルをディレクトリ階層ではなく「オブジェクト」としてフラットな名前空間に格納し、各オブジェクトにメタデータを付与できます。
ストレージ方式の分類と使い分け
クラウドストレージには3つの方式があり、用途によって適切なものが異なります。
| 方式 | データ単位 | アクセス特性 | 主な用途 |
|---|---|---|---|
| ブロックストレージ | 固定サイズブロック | 低レイテンシ・高IOPS | DB、OS起動ディスク |
| ファイルストレージ | ファイル(階層構造) | POSIX準拠・共有アクセス | NFSマウント、共有フォルダ |
| オブジェクトストレージ | オブジェクト(フラット) | HTTP API経由・高スループット | ログ、メディア、バックアップ |
Cloud Storageはオブジェクトストレージに分類されます。HTTP(REST / gRPC)経由でアクセスするため、低レイテンシが必要なデータベース用途には適しませんが、ペタバイト規模のデータを低コストで保存し、BigQueryやVertex AIと直接連携できる点が強みです。
Google Cloudにおけるストレージサービスの全体像
ストレージ設計の第一歩は、ワークロードに応じた適切なサービスの選択です。
| サービス | 方式 | 最大容量 | レイテンシ目安 | 想定ワークロード |
|---|---|---|---|---|
| Persistent Disk | ブロック | 64 TiB/ディスク | サブミリ秒 | VM接続ディスク、DB |
| Hyperdisk | ブロック | 64 TiB/ディスク | サブミリ秒 | 高IOPS要求のDB |
| Filestore | ファイル | 100 TiB | ミリ秒 | NFS共有、レンダリング |
| Managed Lustre | ファイル | ペタバイト級 | サブミリ秒 | HPC、AI/ML学習 |
| NetApp Volumes | ファイル | 100 TiB | ミリ秒 | NFS/SMBマルチプロトコル |
| Cloud Storage | オブジェクト | 無制限 | 数十ミリ秒 | ログ、メディア、データレイク |
IOPS重視のトランザクション処理にはHyperdisk、POSIX準拠の共有ファイルシステムが必要ならFilestore、大規模データの長期保存・分析にはCloud Storageが適しています。
設計プロセス|3ステップでストレージ戦略を策定する
Cloud Storageの設計は「要件定義 → オプション評価 → 構成決定」の3ステップで進めます。
ステップ1: 要件を定義する
設計の出発点は、ワークロードの特性を正確に把握することです。以下のチェックリストで要件を洗い出します。
容量とデータ特性
- 初期データ量と年間増加率(例: 初年度1 TB、年率30%増)
- オブジェクトの平均サイズ(小ファイル中心か大ファイル中心か)
- データの更新頻度(Write Once Read Many か頻繁更新か)
パフォーマンス要件
- 想定スループット(GB/s単位)
- 想定リクエストレート(ops/s単位)
- 許容レイテンシ(ミリ秒単位)
可用性と耐久性
- 許容ダウンタイム(SLA目標: 99.95% or 99.99%)
- RPO(Recovery Point Objective): 許容データ損失時間
- RTO(Recovery Time Objective): 復旧目標時間
セキュリティとコンプライアンス
- データ暗号化の要件(Google管理鍵 / CMEK / CSEK)
- アクセス制御の粒度(バケット単位 / オブジェクト単位)
- データ保持規制(金融業界の7年保持義務など)
コスト制約
- 月額予算上限
- コスト最適化の優先度(パフォーマンスとのトレードオフ許容度)
ステップ2: ストレージクラスを評価する
Cloud Storageは4つのストレージクラスを提供しています。アクセス頻度と保存期間に応じた選択がコスト最適化の鍵です。
| クラス | 最小保存期間 | 保存料金(東京) | 読取オペレーション(1万回) | 適した用途 |
|---|---|---|---|---|
| Standard | なし | $0.023/GB/月 | $0.004 | 頻繁にアクセスするデータ |
| Nearline | 30日 | $0.016/GB/月 | $0.01 | 月1回程度のアクセス |
| Coldline | 90日 | $0.006/GB/月 | $0.05 | 四半期に1回程度 |
| Archive | 365日 | $0.0025/GB/月 | $0.50 | 年1回以下のアクセス |
選定の判断基準:
- 30日以内に再アクセスする可能性が高いデータ → Standard
- DR用バックアップ(月次テスト復元あり) → Nearline
- コンプライアンス用の長期保管(年次監査のみ) → Coldline
- 法定保存義務があり滅多にアクセスしないデータ → Archive
ストレージクラスの料金は定期的に改定されます。最新の正確な料金はCloud Storage の料金ページで確認してください。
ステップ3: 構成を決定する
要件とストレージクラスが決まったら、バケット構成・ロケーション・ライフサイクルルールを具体化します。詳細は以降のセクションで解説します。
バケット設計|命名規則・ロケーション・アクセス制御
バケットはCloud Storageにおけるデータの最上位コンテナです。一度作成すると名前やロケーションは変更できないため、設計段階で慎重に決定する必要があります。
バケット命名のベストプラクティス
Cloud Storageのバケット名はグローバルに一意である必要があります。
推奨パターン: {プロジェクトID}-{用途}-{環境}
- 例:
myproject-logs-prod,myproject-assets-staging
避けるべきパターン:
- 個人情報や機密情報を含む名前(バケット名はURLに含まれるため)
- 連番のみ(
bucket1,bucket2): 用途が不明になる - 長すぎる名前(63文字が上限)
ロケーション選択の3つの選択肢
| ロケーションタイプ | 可用性SLA(Standard) | コスト | 適した用途 |
|---|---|---|---|
| リージョン(例: asia-northeast1) | 99.9% | 低い | レイテンシ重視、単一拠点のアプリ |
| デュアルリージョン(例: asia1) | 99.95% | 中程度 | 地理冗長性が必要なケース |
| マルチリージョン(例: asia) | 99.95% | 高い | グローバル配信、最大可用性 |
日本向けのWebアプリケーションであれば asia-northeast1(東京)のリージョンバケットが、コストとレイテンシの両面で最も合理的です。災害対策が必要な場合は asia1(東京 + 大阪)のデュアルリージョンを検討します。
アクセス制御の設計方針
Cloud Storageには2つのアクセス制御モデルがあります。
均一アクセス制御(Uniform) — 推奨
- バケットレベルのIAMポリシーのみでアクセスを管理
- シンプルで監査しやすい
- 新規バケットのデフォルト
きめ細かいアクセス制御(Fine-grained)
- オブジェクト単位でACL(Access Control List)を設定可能
- レガシーシステムとの互換性が必要な場合に使用
特別な理由がなければ、均一アクセス制御を選択してください。IAMポリシーによるバケット単位の管理の方が、運用負荷が低く、意図しないアクセス許可のリスクも抑えられます。
ライフサイクル管理とAutoclass|ストレージコストの自動最適化
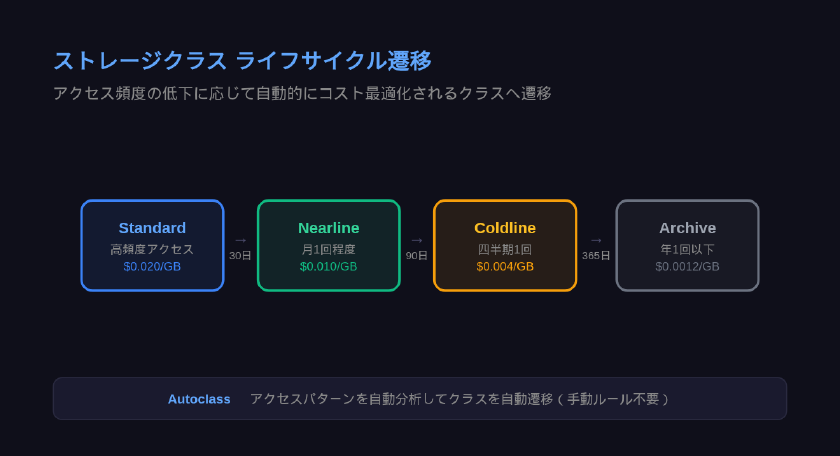
データのアクセス頻度は時間とともに変化します。作成直後は頻繁にアクセスされるログファイルも、3か月後にはほぼ参照されなくなるケースが一般的です。ライフサイクル管理は、この変化に合わせてストレージクラスの自動切り替えや削除を実現する機能です。
ライフサイクルルールの設計例
{
"rule": [
{
"action": {"type": "SetStorageClass", "storageClass": "NEARLINE"},
"condition": {"age": 30, "matchesStorageClass": ["STANDARD"]}
},
{
"action": {"type": "SetStorageClass", "storageClass": "COLDLINE"},
"condition": {"age": 90, "matchesStorageClass": ["NEARLINE"]}
},
{
"action": {"type": "SetStorageClass", "storageClass": "ARCHIVE"},
"condition": {"age": 365, "matchesStorageClass": ["COLDLINE"]}
},
{
"action": {"type": "Delete"},
"condition": {"age": 2555}
}
]
}
この例では、Standard → 30日後にNearline → 90日後にColdline → 1年後にArchive → 7年後に削除、という流れを自動化しています。
Autoclassによるハンズフリー最適化
ライフサイクルルールはアクセスパターンを事前に予測して設定する必要がありますが、Autoclassを使えばGoogle Cloudが実際のアクセス頻度を監視し、ストレージクラスを自動で切り替えます。
Autoclassが有効なケース:
- アクセスパターンが予測しにくいデータ(ユーザーアップロードファイルなど)
- 多種多様なデータが混在するバケット
- ライフサイクルルールの設計・運用コストを削減したい場合
Autoclassが不向きなケース:
- アクセスパターンが明確に予測できるデータ(月次バッチ処理のログなど)
- Nearline/Coldline/Archiveの最小保存期間に起因する早期削除料金を避けたい場合
セキュリティ設計|暗号化・VPC Service Controls・署名付きURL
暗号化の3つの選択肢
Cloud Storageに保存されるデータは、デフォルトでGoogleが管理する鍵(GMEK)で暗号化されます。より厳格な暗号化要件がある場合は、以下の選択肢があります。
| 暗号化方式 | 鍵の管理者 | 鍵のローテーション | 適した要件 |
|---|---|---|---|
| Google管理鍵(GMEK) | 自動 | 一般的な用途 | |
| 顧客管理暗号鍵(CMEK) | ユーザー(Cloud KMS) | ユーザー設定 | コンプライアンス要件あり |
| 顧客指定暗号鍵(CSEK) | ユーザー(自前管理) | ユーザー運用 | 最高レベルの制御 |
金融業界や医療業界などの規制対象データには、Cloud KMSを使ったCMEKが推奨されます。鍵のローテーション間隔やアクセス監査ログの設定も併せて設計してください。
VPC Service Controlsによるデータ流出防止
VPC Service Controlsは、Cloud Storageバケットの周囲にセキュリティ境界(ペリメータ)を設定し、境界外からのアクセスやデータ持ち出しを制限する機能です。
設計上の考慮点:
- サービスペリメータ内にCloud Storageと関連するBigQuery・Dataflow等のサービスをまとめて含める
- ペリメータ外のサービスからのアクセスが必要な場合はイングレスルールを明示的に設定
- テスト環境では「ドライランモード」で影響範囲を事前確認
署名付きURLによる一時的アクセス権の付与
外部ユーザーやサービスに対して、Google Cloudアカウントなしでオブジェクトへの一時的アクセスを許可する場合は、署名付きURL(Signed URL)を使用します。
from google.cloud import storage
import datetime
def generate_signed_url(bucket_name, blob_name):
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
url = blob.generate_signed_url(
version="v4",
expiration=datetime.timedelta(hours=1),
method="GET",
)
return url
署名付きURLの有効期間は最大7日ですが、セキュリティの観点から1時間以内に設定することが推奨されます。
パフォーマンス最適化|スループット・リクエストレート・キャッシュ戦略
オブジェクト命名とリクエスト分散
Cloud Storageは内部的にオブジェクトキーの先頭部分でパーティショニングを行います。連番プレフィクス(0001/, 0002/)を使うと、特定のパーティションにリクエストが集中し、スループットが低下する場合があります。
推奨: ハッシュプレフィクスやタイムスタンプの逆順配置で、リクエストを均等に分散させます。
# 非推奨: 連番プレフィクス
logs/2026/02/24/file001.log
logs/2026/02/24/file002.log
# 推奨: ハッシュプレフィクス
a3f2/logs/2026/02/24/file001.log
b7c1/logs/2026/02/24/file002.log
アップロード方式の選択
| 方式 | 適したファイルサイズ | 特徴 |
|---|---|---|
| シンプルアップロード | 5 MB以下 | 単一リクエスト |
| マルチパートアップロード | 5 MB〜5 TB | 並列分割転送 |
| 再開可能アップロード | 任意(大容量推奨) | 中断時の再開が可能 |
大容量ファイルのアップロードでは、再開可能アップロード(Resumable Upload)を標準として採用してください。ネットワーク障害時に転送済みチャンクの再送が不要になり、転送の信頼性が向上します。
Anywhere Cacheによる読み取り高速化
Anywhere Cacheは、Cloud Storageのデータをリージョン内のSSDキャッシュに配置し、読み取りレイテンシを短縮する機能です。
- キャッシュヒット時は通常の数十ミリ秒から大幅にレイテンシが短縮される
- 最大2.5 TB/sのスループットに対応
- AI/MLの推論ワークロードやコンテンツ配信で有効
- キャッシュ対象はオブジェクト単位で自動管理
コスト最適化|ワークロード別の料金シミュレーション
Cloud Storageの料金は「保存料金 + オペレーション料金 + ネットワーク料金」の3軸で構成されます。
料金構成の内訳
保存料金: GB/月あたりの単価 × データ量。ストレージクラスによって大きく異なります。
オペレーション料金: APIリクエスト単位の課金。クラスAオペレーション(書込・メタデータ更新)とクラスBオペレーション(読取・一覧取得)でそれぞれ料金が異なり、低頻度アクセスクラスほどオペレーション単価が高くなります。
ネットワーク料金: 同一リージョン内のGoogle Cloudサービスからの読み取りは無料。外部インターネットへの下り(egress)が主なコスト要因です。
ワークロード別コスト試算例
ケース1: Webアプリのメディアファイル保管(東京リージョン)
- データ量: 500 GB(Standard)
- 月間読取: 100万回
- ネットワーク下り: 50 GB/月
- 概算月額: 約$12(保存) + $0.4(読取) + 約$6(下り) ≒ 約$18/月
ケース2: ログのアーカイブ保管(東京リージョン)
- データ量: 10 TB(Archive)
- 月間読取: 100回(年次監査用)
- ネットワーク下り: 10 GB/月
- 概算月額: 約$25(保存) + $5(読取) + 約$1.2(下り) ≒ 約$31/月
同じ10 TBをStandardで保管すると月約$230になるため、アクセス頻度に応じたクラス選択だけで約7.5倍のコスト差が生じます。
コスト最適化チェックリスト
- アクセスパターンが不明なバケットにAutoclassを有効化したか
- ライフサイクルルールで不要データの自動削除を設定したか
- Soft Deleteの保持期間を過剰に長くしていないか(デフォルト7日)
- Cloud CDNやAnywhere Cacheで下り転送料金を削減できないか
- 早期削除料金が発生しないようストレージクラスと保存期間を整合させたか
AWS S3・Azure Blobとの比較|3大クラウドのオブジェクトストレージ設計差異
Cloud Storageを選定する際に、他クラウドとの比較は避けて通れません。以下はストレージ設計に影響する主要な違いです。
| 比較項目 | Cloud Storage (GCS) | Amazon S3 | Azure Blob Storage |
|---|---|---|---|
| 耐久性 | 99.999999999% (11ナイン) | 99.999999999% | 99.999999999% |
| 最大オブジェクトサイズ | 5 TiB | 50 TB | 約190.7 TiB (ブロックBlob) |
| ストレージ階層 | 4クラス | 8クラス(Standard系4種 + Glacier系3種 + Express One Zone) | 4層 (Hot/Cool/Cold/Archive) |
| 自動階層化 | Autoclass | Intelligent-Tiering | ライフサイクルポリシー |
| 強整合性 | デフォルトで強整合性 | デフォルトで強整合性 | デフォルトで強整合性 |
| 分析連携 | BigQuery直接クエリ | Athena/Redshift Spectrum | Synapse Analytics |
| ファイルシステムマウント | Cloud Storage FUSE | Mountpoint for S3 | BlobFuse2 |
| AI/ML連携 | Vertex AI直接連携 | SageMaker S3連携 | Azure ML Blob連携 |
Cloud Storage固有の設計上の強み:
- BigQueryとのネイティブ連携: 外部テーブルとして直接クエリ可能。ETLパイプラインなしでデータレイク上の分析が可能
- Turbo Replication: デュアルリージョン構成で、書き込みから15分以内のレプリケーション保証(RPO 0に近い構成が可能)
- Hierarchical Namespace(階層名前空間): ディレクトリレベルの原子的リネーム・移動をサポート。Apache Hive/Spark等のビッグデータ処理との親和性が高い
AWS S3固有の設計上の強み:
- Glacier Deep Archive: 超長期保管に特化した最低価格帯のストレージクラス
- S3 Object Lambda: 読み取り時にLambdaでデータ変換を自動適用
- エコシステムの広さ: サードパーティツールのS3互換APIサポートが最も充実
Azure Blob固有の設計上の強み:
- Azure Data Lake Storage Gen2: Blob Storageの上にHDFS互換のファイルシステムを提供
- Microsoft 365連携: SharePoint・OneDriveとの統合が容易
AI/MLワークロード向けのストレージ設計
AI/MLパイプラインではライフサイクルの各段階(データ準備・学習・推論・アーカイブ)でストレージ要件が大きく異なります。Google Cloudの公式ガイドラインでは、段階ごとのハイブリッドアプローチを推奨しています。
MLライフサイクル別のストレージ選定
| ライフサイクル段階 | 推奨サービス | 選定理由 |
|---|---|---|
| データ準備 | Cloud Storage(Standard) | スケーラビリティとコスト効率のバランス |
| 学習(大ファイル) | Cloud Storage + FUSE | 50MB以上のファイルに高スループットで対応 |
| 学習(小ファイル・ランダムI/O) | Managed Lustre | サブミリ秒レイテンシ、1 TB/sスループット |
| 推論 | Cloud Storage FUSE + Anywhere Cache | 低レイテンシ読み取りと動的スケーリング |
| アーカイブ | Cloud Storage(Nearline/Archive) | 長期保管の低コスト化 |
チェックポイント保存の設計
大規模モデルの学習ではGPU/TPUの遊休時間を最小化することが重要です。チェックポイントの書き込み中はアクセラレータが待機状態になるため、高スループットのストレージを選択し、書き込み時間を短縮します。
- Cloud Storage FUSE: 並列ダウンロード・アップロード機能で大容量チェックポイントの転送を高速化
- Managed Lustre: 小ファイルの頻繁なチェックポイント保存に最適。POSIXインターフェースによりフレームワーク側のコード変更が不要
海外のストレージ設計トレンド|日本の実務に活かす知見
海外(主に米国)のクラウドストレージ設計に関する議論では、日本国内の情報ではあまり取り上げられない視点がいくつかあります。
システムデザインの観点:ストレージの内部アーキテクチャ
米国のテックコミュニティでは、Dropboxのようなクラウドストレージサービスを「設計する側」の視点でアーキテクチャを議論する文化が根付いています。その中でストレージ設計に直接応用できる概念として、以下が挙げられます。
Content-Defined Chunking(CDC): ファイルを固定サイズではなくコンテンツの境界で分割する手法です。ファイルの一部が変更された場合でも、変更されたチャンクのみを再転送できるため、差分同期の効率が向上します。Cloud Storageの「コンポーズ(Compose)」機能と組み合わせることで、大規模データパイプラインでの差分更新を効率化できます。
デルタ同期: ファイル全体ではなく変更差分のみを転送する設計です。オンプレミスからCloud Storageへの定期データ同期やハイブリッドクラウド構成で、ネットワーク帯域とegress料金の両方を節約できます。
Zero-Disk Architectureの動向
2025年以降、クラウドストレージの分野では「Zero-Disk Architecture」と呼ばれるコンセプトが注目されています。従来のブロックストレージ(仮想ディスク)への依存を減らし、オブジェクトストレージを主軸としたアーキテクチャに移行する考え方です。
Cloud Storage FUSEやManaged Lustreの登場により、「ブロックストレージが必要だった領域」の一部をオブジェクトストレージやファイルストレージで代替できるようになっています。ストレージ設計の際は、「本当にブロックストレージが必要か」を改めて検討する価値があります。
コンフリクト解決パターン
複数のクライアントやサービスが同一オブジェクトに同時書き込みを行うシナリオでは、コンフリクト解決戦略の設計が必要です。Cloud Storageは「最後の書き込みが優先(Last-Writer-Wins)」の整合性モデルを採用しており、オブジェクトの世代番号(Generation Number)を使った楽観的ロックで同時更新の衝突を検知できます。
# 世代番号を使った条件付き更新(gsutil)
gsutil -h "x-goog-if-generation-match:12345" cp local-file.txt gs://bucket/object.txt
データ保護の設計|バージョニング・Soft Delete・保持ポリシー
データの誤削除や不正操作に対する防御層を複数設計しておくことで、インシデント発生時の復旧を迅速化できます。
防御層の組み合わせ
| 機能 | 保護対象 | 復旧方法 | コスト影響 |
|---|---|---|---|
| オブジェクトバージョニング | 上書き・削除 | 旧バージョンから復元 | 全バージョン分の保存料金 |
| Soft Delete | 削除 | 保持期間内に復元 | Soft Delete期間中の保存料金 |
| 保持ポリシー(Bucket Lock) | 早期削除 | 保持期間中は削除不可 | 追加料金なし |
| Object Retention Lock | オブジェクト単位の削除制限 | 保持期間中は削除不可 | 追加料金なし |
推奨構成例(一般的なプロダクション環境):
- バージョニングを有効化(過去3世代を保持するライフサイクルルールと併用)
- Soft Deleteの保持期間を7日に設定(デフォルト値)
- コンプライアンス要件がある場合のみBucket Lockを追加
設計チェックリスト|本番構築前の最終確認
Cloud Storageの設計を本番環境に適用する前に、以下のチェックリストで漏れがないか確認してください。
要件定義
- データ量の初期値と増加見込みを数値化したか
- パフォーマンス要件(スループット・IOPS・レイテンシ)を明確にしたか
- SLAとRPO/RTOの目標を設定したか
ストレージ構成
- ストレージクラスをアクセスパターンに基づいて選択したか
- バケットのロケーションをレイテンシ・コスト・冗長性の観点で決定したか
- バケット命名規則をチームで合意したか
コスト管理
- ライフサイクルルールまたはAutoclassを設定したか
- 不要データの自動削除ルールを設定したか
- Cloud Billing Alertで予算超過を検知する仕組みを用意したか
セキュリティ
- 均一アクセス制御(Uniform)を選択したか
- 暗号化方式(GMEK / CMEK / CSEK)を要件に合わせて決定したか
- パブリック公開を必要最小限に制限し、組織ポリシーで制御したか
- VPC Service Controlsの適用を検討したか
データ保護
- バージョニングの有効/無効を判断したか
- Soft Deleteの保持期間を設定したか
- 規制要件がある場合、保持ポリシーを設定したか
運用
- Cloud Audit Logsでアクセスログを有効化したか
- Cloud Monitoringでストレージ容量・リクエスト数のアラートを設定したか
- 障害復旧手順をドキュメント化したか
よくある設計ミスとその対策
ミス1: ストレージクラスの選択ミスによる早期削除料金
Nearline(30日)・Coldline(90日)・Archive(365日)には最小保存期間があり、期間内に削除すると残存期間分の保存料金が発生します。一時的なデータ処理にColdlineを使ってしまい、処理後すぐ削除して不必要な料金が発生するケースがよく見られます。
対策: 保存期間が短いデータはStandardを使用するか、Autoclassに委ねる。
ミス2: マルチリージョンの過剰適用
「可用性は高い方がいい」とマルチリージョンを選択するケースがありますが、マルチリージョンはリージョンバケットと比較して保存料金・ネットワーク料金ともに高くなります。単一リージョンからのアクセスが大部分であれば、リージョンバケット + Cloud CDNの組み合わせの方がコスト効率に優れます。
対策: ロケーション選択はアクセス元の地理分布に基づいて判断する。
ミス3: バケットの粒度が粗すぎる
1つのバケットにアクセスパターンの異なるデータ(頻繁アクセスのメディアファイルと年次監査用のログ)を混在させると、ストレージクラスの最適化やアクセス制御が難しくなります。
対策: 用途・アクセスパターン・セキュリティ要件が異なるデータは別バケットに分離する。
まとめ
Cloud Storageの設計は、技術的な機能選択だけでなく、コストとセキュリティと運用性のバランスを取る総合的な判断です。設計プロセスの要点を整理します。
- 要件定義が出発点: データ量・パフォーマンス・SLA・コンプライアンスの4軸で要件を数値化する
- ストレージクラスはアクセス頻度で決める: Standard → Nearline → Coldline → Archiveの4段階をライフサイクルに沿って設計する
- バケット設計は変更不可を前提にする: 命名規則・ロケーション・アクセス制御モデルは作成後に変更できないため、初期設計が重要
- コスト最適化はAutoclass + ライフサイクルルールの併用: アクセスパターンが予測可能なデータはルールベース、不明なデータはAutoclassに委ねる
- セキュリティは多層防御: IAM + 暗号化 + VPC Service Controls + 署名付きURLの組み合わせで、最小権限の原則を実装する
- AI/MLワークロードはライフサイクル別にストレージを使い分ける: 学習フェーズにはManaged LustreやCloud Storage FUSE、推論にはAnywhere Cacheを活用する
最新の料金やサービス仕様はCloud Storage ドキュメントで確認してください。