
マルチスレッドプログラムで共有変数の値が意図せず書き換わった経験はないでしょうか。複数のスレッドが同時に同じデータへ読み書きすると、実行タイミング次第で結果が変わる「競合状態(Race Condition)」が発生します。Mutex(ミューテックス)は、この問題を防ぐために設計された排他制御の基本メカニズムです。
並行処理と並列処理の違い ― Mutexが必要になる前提知識
Mutexの動作を正しく理解するには、「並行(Concurrency)」と「並列(Parallelism)」の区別が欠かせません。
並行処理は、複数タスクの実行期間を重ね合わせる手法です。シングルコアCPUでもタイムスライスで切り替えれば実現できます。一方、並列処理は物理的に複数のコアでタスクを同時実行します。
| 観点 | 並行処理(Concurrency) | 並列処理(Parallelism) |
|---|---|---|
| 実行形態 | 時間的に交互に切り替え | 物理的に同時実行 |
| 必要な環境 | シングルコアでも可能 | マルチコアCPU |
| 問題の発生条件 | 共有リソースへのアクセスが重なった瞬間 | 同左 |
どちらの場合でも、複数のスレッドが同じメモリ領域にアクセスした瞬間に競合状態が生まれます。この競合を防ぐ仕組みのひとつがMutexです。
Mutex(ミューテックス)の定義と動作原理
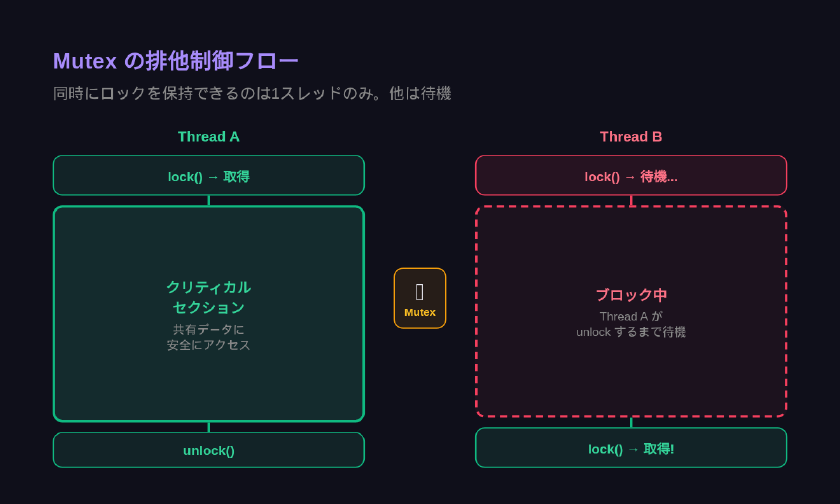
Mutexは Mutual Exclusion(相互排他) の略称です。あるリソースに対して、一度に1つのスレッドだけがアクセスできるよう制限します。
動作は3ステップで構成されます。
- ロック取得: スレッドがMutexのロックを要求します。他のスレッドが保持中であれば、解放されるまで待機します
- クリティカルセクション実行: ロックを取得したスレッドだけが共有リソースを操作します
- アンロック: 処理完了後にロックを解放し、待機中の次のスレッドへ所有権が渡ります
Mutexの重要な特性は 「所有権」 の概念です。ロックを取得したスレッドだけがアンロック操作を行えます。後述するセマフォでは、どのスレッドでもカウンターを操作できるため、この点がMutex固有の安全性につながります。
競合状態が引き起こす具体的な問題
Mutexなしで2つのスレッドが同じ変数を同時にインクリメントすると、次のような事態が起きます。
# 想定: counter = 0 → 各スレッドが1000回インクリメント → 期待値 2000
スレッドA: counter の値 5 をレジスタに読み込み
スレッドB: counter の値 5 をレジスタに読み込み(Aの書き戻し前)
スレッドA: レジスタを +1 して 6 を書き戻し
スレッドB: レジスタを +1 して 6 を書き戻し ← 本来は7になるべき
CPUがインクリメントを「読み込み → 加算 → 書き戻し」の3命令に分割するため、割り込みのタイミング次第でデータが消失します。最終結果は2000にならず、実行のたびに異なる値になります。
言語別のMutex実装パターン
Python ― threading.Lock
import threading
counter = 0
lock = threading.Lock()
def increment(n):
global counter
for _ in range(n):
lock.acquire()
counter += 1
lock.release()
threads = [threading.Thread(target=increment, args=(100000,)) for _ in range(4)]
for t in threads:
t.start()
for t in threads:
t.join()
print(f"counter = {counter}") # 常に 400000
with lock: 構文を使えば、例外発生時でも確実にアンロックされます。
def increment_safe(n):
global counter
for _ in range(n):
with lock:
counter += 1
C / POSIX ― pthread_mutex
#include <pthread.h>
#include <stdio.h>
int counter = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *worker(void *arg) {
for (int i = 0; i < 100000; i++) {
pthread_mutex_lock(&mutex);
counter++;
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main(void) {
pthread_t t1, t2;
pthread_create(&t1, NULL, worker, NULL);
pthread_create(&t2, NULL, worker, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("counter = %d\n", counter); // 常に 200000
pthread_mutex_destroy(&mutex);
return 0;
}
POSIXのMutexには4つのタイプがあり、pthread_mutexattr_settype で変更できます。
| タイプ | 同一スレッドの再ロック | 他スレッドによるアンロック |
|---|---|---|
PTHREAD_MUTEX_NORMAL | デッドロック発生 | 未定義動作 |
PTHREAD_MUTEX_ERRORCHECK | エラー返却 | エラー返却 |
PTHREAD_MUTEX_RECURSIVE | カウンター増加(許可) | エラー返却 |
PTHREAD_MUTEX_DEFAULT | 実装依存 | 実装依存 |
再帰的なアルゴリズムでロックが必要な場合は PTHREAD_MUTEX_RECURSIVE が有効です。ただし、ロック回数とアンロック回数が一致しないとデッドロックに陥るため、設計に注意が求められます。
Go ― sync.Mutex と sync.RWMutex
package main
import (
"fmt"
"sync"
)
func main() {
var mu sync.Mutex
var wg sync.WaitGroup
counter := 0
for i := 0; i < 4; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for j := 0; j < 100000; j++ {
mu.Lock()
counter++
mu.Unlock()
}
}()
}
wg.Wait()
fmt.Println("counter =", counter) // 常に 400000
}
Goでは sync.RWMutex を使うことで、読み取りロックと書き込みロックを分離できます。読み取りが多く書き込みが少ないワークロード(キャッシュサーバーなど)では、RWMutexの方がスループットが向上します。
var rwmu sync.RWMutex
var cache = make(map[string]string)
// 読み取り: 複数goroutineが同時実行可能
func get(key string) string {
rwmu.RLock()
defer rwmu.RUnlock()
return cache[key]
}
// 書き込み: 1 goroutineだけが実行可能
func set(key, value string) {
rwmu.Lock()
defer rwmu.Unlock()
cache[key] = value
}
Rust ― std::sync::Mutex
Rustでは、Mutexが型システムに組み込まれています。Mutex<T> でラップされたデータには、ロックを取得しない限りアクセスできません。
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..4 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
for _ in 0..100000 {
let mut num = counter.lock().unwrap();
*num += 1;
// スコープを抜けるとMutexGuardがdropされ自動アンロック
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("counter = {}", *counter.lock().unwrap()); // 常に 400000
}
Rustの Mutex<T> は、ロック未取得の状態で内部データにアクセスしようとするとコンパイルエラーになります。これにより、ロック忘れによるデータ競合がコンパイル時に検出されます。
C++ ― std::mutex と std::lock_guard
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
int counter = 0;
std::mutex mtx;
void worker() {
for (int i = 0; i < 100000; i++) {
std::lock_guard<std::mutex> lock(mtx);
counter++;
}
// スコープを抜けるとlock_guardのデストラクタが自動アンロック
}
int main() {
std::vector<std::thread> threads;
for (int i = 0; i < 4; i++) {
threads.emplace_back(worker);
}
for (auto &t : threads) {
t.join();
}
std::cout << "counter = " << counter << std::endl; // 常に 400000
return 0;
}
C++17では std::scoped_lock を使うと、複数のMutexをデッドロックなしで一括取得できます。
std::mutex m1, m2;
void safe_transfer() {
std::scoped_lock lock(m1, m2); // m1 と m2 を同時にロック
// デッドロックなしで両方のリソースを安全に操作
}
Mutexの種類 ― 4つのバリエーション
Mutexには用途に応じた複数の種類があります。
| 種類 | 動作 | 用途 |
|---|---|---|
| 通常Mutex(Binary Mutex) | locked / unlocked の2状態 | 最もシンプルな排他制御 |
| 再帰Mutex(Recursive Mutex) | 同一スレッドが複数回ロック取得可能 | 再帰関数内でのロック |
| 公平Mutex(Fair Mutex) | FIFOキューで待機順を保証 | スタベーション防止 |
| 時限Mutex(Timed Mutex) | タイムアウト付きロック取得 | デッドロック検出・回避 |
通常のMutexでは、同一スレッドが二重にロックするとデッドロックが起きます。再帰Mutexはこの問題を回避しますが、ロック回数の管理が必要になるため、設計の複雑さが増します。
時限Mutex(C++の std::timed_mutex、Go の context.WithTimeout)は、一定時間内にロック取得できなければ処理を中断できるため、デッドロックからの自動復帰に役立ちます。
Mutexとセマフォの違い
「Mutexはカウンター上限が1のセマフォ」と表現されることがありますが、設計思想には明確な違いがあります。
| 比較軸 | Mutex | セマフォ |
|---|---|---|
| 同時アクセス数 | 常に1スレッドのみ | カウンターで上限を設定(複数可) |
| アンロック権限 | ロックしたスレッドだけ | 任意のスレッドがカウンター操作可能 |
| 状態管理 | 2値(locked / unlocked) | 0以上の整数値 |
| 所有権の概念 | あり | なし |
| 典型的な用途 | 共有変数の排他書き込み | 接続プールの同時利用数制限 |
セマフォには「所有権」の概念がないため、スレッドAが取得したセマフォをスレッドBが解放できます。この柔軟性はプロデューサー・コンシューマーパターンで便利ですが、誤用によるバグを招きやすい側面もあります。
Mutexとモニターの関係
Java の synchronized ブロックや C# の lock 文は、内部的に モニター という仕組みを使っています。モニターは「Mutex + 条件変数(Condition Variable)」を組み合わせた高レベルの同期構造です。
// Java: synchronized はモニターを暗黙的に使用
public synchronized void increment() {
counter++; // 自動でロック取得・解放
}
// C#: lock 文もモニターベース
private readonly object _lock = new();
public void Increment() {
lock (_lock) {
counter++;
}
}
モニターはプロセス内のスレッド間でのみ機能するため軽量です。プロセスをまたいだ排他制御が必要な場合は、OS提供の名前付きMutex(System.Threading.Mutex や POSIX の共有Mutex)を使います。
デッドロック・スタベーション・ライブロック ― Mutex利用時の3つの落とし穴
Mutexの使用には、いくつかの典型的な問題が伴います。
デッドロック
2つ以上のスレッドが互いのロック解放を待ち続け、永久に停止する状態です。
スレッドA: mutex_1 をロック → mutex_2 のロック待ち
スレッドB: mutex_2 をロック → mutex_1 のロック待ち
→ 両方が永久に停止
防止策:
- ロック取得順序の統一: すべてのスレッドが同じ順序でロックを取得する(例: 常にmutex_1 → mutex_2の順)
- タイムアウト付きロック: 一定時間で取得できなければロックを放棄して再試行する
- スコープドロック: C++ の
std::scoped_lockのように、複数のMutexを一括取得する機構を利用する
スタベーション(飢餓状態)
特定のスレッドが長時間ロックを取得できず、処理が進まない状態です。公平Mutex(Fair Mutex)を使ってFIFO順を保証すれば防止できます。
ライブロック
スレッドはアクティブに動いているものの、互いに譲り合って永遠に処理が進まない状態です。廊下で向かい合った2人が同時に左右に避けて永遠にすれ違えない状況に似ています。
| 現象 | 状態変化 | 進捗 |
|---|---|---|
| デッドロック | なし(完全停止) | なし |
| ライブロック | あり(動き続ける) | なし(結果は出ない) |
| スタベーション | 他スレッドは進行中 | 特定スレッドのみ停止 |
ロック粒度の設計 ― 粗粒度と細粒度のトレードオフ
Mutexの保護範囲をどこまで広くするかは、パフォーマンスに直結する設計判断です。
| 粗粒度(Coarse-grained) | 細粒度(Fine-grained) | |
|---|---|---|
| ロック数 | 少ない(広い範囲を1つで保護) | 多い(小さい単位ごとに保護) |
| 実装の複雑さ | シンプル | デッドロックリスク増 |
| 並行性能 | 低い(ロック競合が頻発) | 高い(各スレッドが独立に動作) |
| メモリ消費 | 少ない | Mutexオブジェクト分だけ増加 |
実務では「まず粗粒度で正しく動く実装を作り、プロファイリングでボトルネックを特定してから細粒度に分割する」というアプローチが推奨されます。最適化の前に計測が必要です。
Mutexの内部実装 ― なぜLinuxのMutexは速いのか
Linuxカーネルでは、Mutexの実装に futex(Fast Userspace Mutex) という仕組みが使われています。
通常のロック操作(ロック対象が空いている場合)は、カーネルへのシステムコールを一切行わず、ユーザー空間のアトミック命令だけで完結します。これが「fast path(高速パス)」です。
他のスレッドがロックを保持していて競合が発生した場合にのみ、カーネルの FUTEX_WAIT システムコールが呼ばれ、スレッドがスリープ状態に移行します。ロックが解放されると FUTEX_WAKE で待機スレッドが起こされます。
この設計により、競合が起きない限りMutexのオーバーヘッドは極めて小さくなります。アプリケーションの大部分ではロック競合が発生しないため、この最適化の効果は大きいです。
優先度逆転問題 ― 宇宙探査機のバグから学ぶ
MutexにはOSのスケジューリングと絡む高度な問題も存在します。その代表例が優先度逆転(Priority Inversion) です。
低優先度のスレッドがMutexを保持している間に中優先度のスレッドがCPUを占有すると、高優先度のスレッドが間接的にブロックされる現象が起きます。
Mars Pathfinderの事例(1997年)
1997年に火星に着陸したNASAの探査機「Mars Pathfinder」は、着陸後に繰り返しシステムリセットが発生するトラブルに見舞われました。原因はVxWorks RTOS上での優先度逆転でした。
- 低優先度の「気象データ収集タスク」がMutexを保持中に、中優先度の「通信タスク」がCPUを占有
- 最高優先度の「情報バス管理タスク」がMutexを取得できず無制限にブロック
- ウォッチドッグタイマーが異常を検知し、システムリセットを繰り返し発動
原因は、該当するMutexの初期化時に 優先度継承(Priority Inheritance) フラグがオフになっていたことでした。地球からソフトウェアパッチを送信し、このフラグをオンに変更したところ問題は解消されました(出典: “What really happened on Mars?” - Glenn Reeves, JPL)。
優先度継承プロトコルでは、Mutexを保持している低優先度スレッドに一時的にブロック中の高優先度を付与します。これにより中優先度スレッドによるプリエンプションを防ぎ、Mutexの保持期間を最短に抑えます。
Mutexの実用的な利用シーン
Mutexは理論上の概念ではなく、日常的なソフトウェア開発で頻繁に使われます。
- ログシステム: 複数スレッドからの同時書き込みを直列化し、ログの文字化けや行の混在を防止
- キャッシュサーバー: インメモリキャッシュの読み書き保護。読み取りが多い場合はRWMutexが効果的
- カウンター・メトリクス収集: リクエスト数やエラー数の正確なカウント
- コネクションプール: データベース接続プールの取得・返却操作の保護
- アプリケーションの多重起動防止: OS提供の名前付きMutexを使い、同一アプリの二重起動を検出
try_lock による非ブロッキング取得
通常の lock() はロックが取得できるまでスレッドをブロックしますが、try_lock() はロック取得の可否を即座に返します。
// Go: TryLock(Go 1.18以降)
if mu.TryLock() {
defer mu.Unlock()
// クリティカルセクション
} else {
// ロック取得失敗 → 別処理にフォールバック
}
// C++: try_lock
if (mtx.try_lock()) {
// クリティカルセクション
mtx.unlock();
} else {
// ロック取得失敗
}
try_lock はUI描画スレッドのように「ブロックしたくないが、可能であればデータを更新したい」場面で有効です。
よくある質問
ミューテックスとは簡単にいうと何ですか?
Mutex(Mutual Exclusion: 相互排他)は、複数のスレッドが同時に動作する環境で、共有データへのアクセスを1スレッドずつに制限する仕組みです。個室のドアロックのように、中に人がいる間は他の人が入れず、出たら次の人が入れます。
並列処理と並行処理はどう違いますか?
並行処理は複数タスクの実行期間を重ね合わせる手法で、シングルコアでも時分割で実現できます。並列処理は物理的に複数コアで同時実行します。Mutexはどちらの場合でも、共有リソースへの同時アクセスが発生する局面で必要です。
セマフォとの使い分けはどうしますか?
排他占有(1スレッドだけがアクセス)が必要な場合はMutex、同時アクセス数に上限を設けたい場合(接続プールの制限など)はセマフォを選択します。Mutexには「ロックしたスレッドだけがアンロックできる」という所有権があり、セマフォにはありません。
デッドロックはどう防ぎますか?
3つの対策が基本です。(1)すべてのスレッドでロック取得順序を統一する(2)タイムアウト付きロックを使い、一定時間で取得できなければ再試行する(3)C++の std::scoped_lock のように、複数Mutexを一括取得する仕組みを活用する。
まとめ
Mutexは並行・並列処理における排他制御の基盤です。ロック取得 → クリティカルセクション実行 → アンロックという3ステップの動作は、C、C++、Go、Rust、Python、Java、C# のいずれでも共通しています。
セマフォとの使い分けは「1スレッド限定ならMutex、N個同時ならセマフォ」が原則です。デッドロック、スタベーション、ライブロックの3つの落とし穴を知った上で、ロック粒度の設計とtry_lockの活用まで意識すれば、安全で効率的な並行プログラムを構築できます。
Mars Pathfinderの優先度逆転問題が示すように、Mutexの設計判断が単なるコードの書き方にとどまらず、システム全体の安定性に直結することも覚えておくべき教訓です。