
AIがコードを書く時代は、すでに始まっています。CursorやClaude Code、GitHub Copilotなどのツールを使えば、自然言語の指示だけでアプリケーションが生成されます。しかし「動くものを作る」ことと「本番環境で運用し続ける」ことの間には、大きな溝があります。
この溝を埋める方法として注目されているのがエージェンティックエンジニアリングです。AIを「コードを書く道具」から「開発プロセス全体を担うチームメンバー」へと昇格させ、人間がアーキテクトとして全体を統制する開発スタイルです。
エージェンティックエンジニアリングの定義
エージェンティックエンジニアリングとは、複数のAIエージェントにソフトウェア開発の実装タスクを委任し、人間が設計・評価・品質保証の責任を担う開発手法です。
テスラの元AIディレクター(Director of AI)であるAndrej Karpathy氏が2026年2月にX(旧Twitter)上でこの概念を提唱し、Google Cloud AIディレクターのAddy Osmani氏が自身のブログで詳細な解説記事を公開したことで、急速に注目を集めました。
従来の「AIにコード生成を頼む」行為がバイブコーディングと呼ばれるのに対し、エージェンティックエンジニアリングでは以下の3つの点で異なります。
| 観点 | バイブコーディング | エージェンティックエンジニアリング |
|---|---|---|
| 対象範囲 | 単発のコード生成 | 設計からテスト・デプロイまでのプロセス全体 |
| 人間の役割 | プロンプトを書く人 | アーキテクト兼品質責任者 |
| AIの使い方 | 1つのAIに都度指示 | 複数エージェントを役割分担させて並行稼働 |
| 品質管理 | 人間が全コードを確認 | CI/CD・リンター・テストで自動検証 |
| 変更への対応 | 毎回プロンプトを書き直す | コンテキストファイルでルールを永続化 |
なぜ今この概念が必要なのか
バイブコーディングが露呈した3つの限界
バイブコーディングは2025年に爆発的に普及しました。プログラミング経験がなくてもアプリを作れる手軽さが多くの人を惹きつけました。しかし、実務に適用するにつれて以下の問題が顕在化しています。
1. セキュリティの盲点
AIが生成するコードには、SQLインジェクション・XSS・認証回りの脆弱性が含まれることがあります。プロンプトだけでセキュリティ要件を完全に伝えるのは困難であり、生成されたコードのレビュー体制がなければ、本番環境にリスクを抱えたままリリースすることになります。
2. 保守不能なコードの蓄積
AIが生成したコードは「動く」ことは保証しますが、読みやすさ・一貫性・将来の変更容易性は保証しません。命名規則のバラつき、不要な依存関係、過剰に複雑な実装が積み重なり、数か月後には「誰も触れないコードベース」が出来上がります。
3. 複雑な要件への非対応
マイクロサービス間の整合性、トランザクション管理、分散システムのエラーハンドリングなど、ソフトウェアの複雑性が一定水準を超えると、単発のプロンプトでは対応できません。コンテキストウィンドウの制約もあり、プロジェクト全体を把握した上での設計判断は人間にしかできません。
開発の制約は「書く速度」から「判断の速度」へ移行した
ソフトウェア開発のボトルネックは時代とともに変遷してきました。
1960-80年代: ハードウェア制約(CPU・メモリが高価)
1990-2000年代: 人的制約(エンジニアの工数が不足)
2010年代: インフラ制約(クラウドが解消)
2020年代後半: アイデアと判断が制約に
AIがコードを高速で生成できるようになった現在、ボトルネックは「何を作るか」「どう設計するか」「品質をどう保証するか」という判断の領域に移っています。エージェンティックエンジニアリングは、この判断に集中するために実装作業をAIに委任する仕組みです。
エージェンティックエンジニアリングの4つの基本原則
原則1: タスクを適切な粒度に分解する
AIエージェントは、明確で限定されたタスクほど高い精度で遂行します。「ECサイトを作って」という曖昧な指示ではなく、「商品一覧APIのエンドポイントを実装して」「カート追加のバリデーションを書いて」のように分解します。
悪い例:
「ユーザー認証機能を実装して」
良い例:
1. JWTトークン生成・検証のユーティリティを実装
2. ログインAPIエンドポイントを作成(email + password)
3. 認証ミドルウェアを実装(トークン検証 + ユーザー取得)
4. パスワードリセットフローを実装
5. 各機能のユニットテストを作成
分解の目安は「1つのエージェントセッションで完結するサイズ」です。概ね1ファイル〜数ファイルの変更で収まる粒度が適しています。
原則2: コンテキストをファイルとして永続化する
エージェントへの指示を毎回プロンプトで書き直すのは非効率です。プロジェクトのルール・アーキテクチャ・コーディング規約をファイルに記述し、エージェントが自動的に参照する仕組みを構築します。
Claude Codeでは CLAUDE.md、GitHub Copilotでは .github/copilot-instructions.md がこの役割を担います。
コンテキストファイルに含めるべき情報:
- プロジェクトのアーキテクチャ概要
- 技術スタック(言語・フレームワーク・バージョン)
- コーディング規約(命名規則・エラーハンドリング方針)
- ディレクトリ構成と各ディレクトリの責務
- テスト方針(カバレッジ基準・テストの種類)
- やってはいけないこと(禁止パターン)
このファイルはプロジェクトのリポジトリにコミットし、チーム全員がAIに同じルールを適用できるようにします。
原則3: 検証の自動化をエージェントの前提条件にする
エージェンティックエンジニアリングでは、AIが生成したコードを人間がすべて目視レビューすることを前提としません。代わりに、自動化された検証レイヤーをエージェントの前後に設置します。
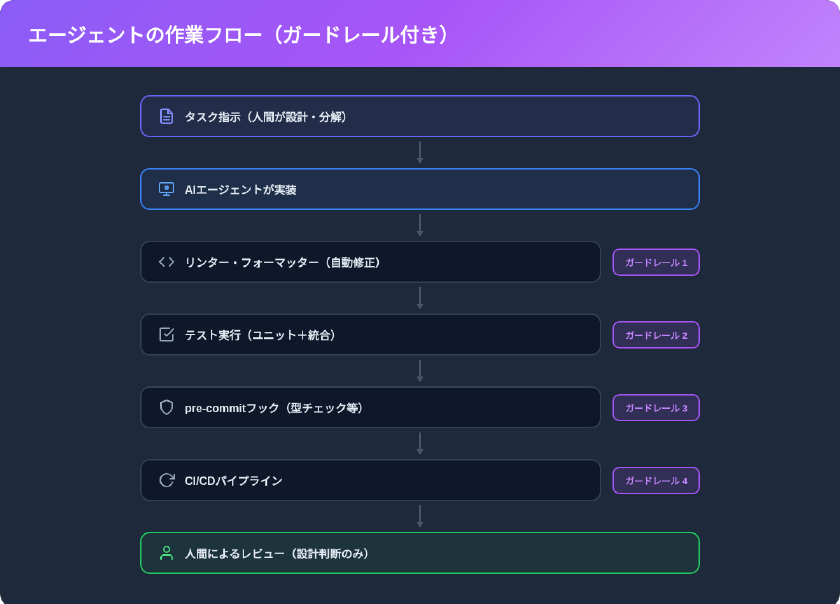
このガードレール設計により、人間のレビュー負荷は「コードの正しさ」から「設計判断の妥当性」へと集約されます。リンターやテストが検出できる問題はエージェントに自動修正させ、人間はアーキテクチャの整合性やビジネスロジックの妥当性に集中します。
原則4: AIの出力は確率的であることを前提に設計する
従来の開発ツール(コンパイラ・リンター・テストフレームワーク)は決定論的です。同じ入力には常に同じ出力が返ります。しかしAIエージェントは確率的であり、同じプロンプトに対して異なるコードを生成する可能性があります。
この不確実性に対処するための設計原則は以下のとおりです。
- フィーチャーブランチで隔離: エージェントの作業は常にmainブランチから分離する
- 小さなコミットを積み重ねる: 問題発生時にすぐ巻き戻せる単位で作業させる
- テストを先に書く: 期待する振る舞いを先に定義し、エージェントはそれを満たすコードを書く
- 複数エージェントの相互レビュー: 実装エージェントとは別のエージェントにレビューを担当させる
AIの確率的な出力と向き合い、その品質を仕組みで担保する能力は、エージェンティックエンジニアリング時代のエンジニアに求められる新しいスキルセットです。
実践的なワークフロー構築
マルチエージェント構成の設計パターン
エージェンティックエンジニアリングでは、複数のAIエージェントを役割ごとに分けて稼働させます。
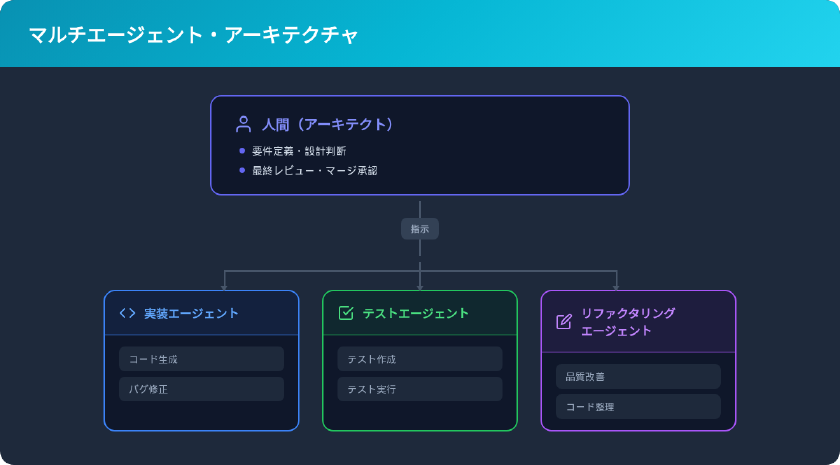
Claude Codeでは Task ツールを使ってサブエージェントを起動し、この役割分担を実現できます。各エージェントは独立したコンテキストで動作するため、相互に干渉しません。
段階的な導入ステップ
エージェンティックエンジニアリングの導入は一度に全てを変える必要はありません。3段階で移行するのが現実的です。
ステップ1: ガードレールの整備(1〜2週間)
まず既存プロジェクトの自動検証基盤を整えます。
- リンター・フォーマッターの設定(ESLint, Prettier, Rustfmtなど)
- テストカバレッジの計測と基準値の設定
- pre-commitフックの導入(型チェック、リントの自動実行)
- CI/CDパイプラインでのテスト自動実行
ステップ2: コンテキストファイルの作成(数日)
プロジェクトの暗黙知をファイルに記述します。
CLAUDE.mdまたは相当するコンテキストファイルの作成- ディレクトリ構成・コーディング規約・テスト方針の明文化
- 禁止パターン・セキュリティ要件の記述
ステップ3: エージェントへのタスク委任を段階的に拡大
最初は低リスクなタスクから始めます。
- テストコードの生成
- 既存コードのリファクタリング
- ドキュメント生成
- 新機能の実装(フィーチャーブランチ上で)
成功体験を積みながら、委任範囲を広げていきます。
ガードレール設計の実践
エージェンティックエンジニアリングの品質を支えるのは、エージェントの能力ではなくガードレールの設計です。
コンテキストファイルによるルールの強制
# CLAUDE.md の例
## 禁止事項
- any型の使用禁止(TypeScript)
- console.logをプロダクションコードに残さない
- テストなしの機能追加は不完了とみなす
## アーキテクチャ
- src/domain/: ビジネスロジック(外部依存なし)
- src/infra/: DB・API等の外部接続
- src/app/: ユースケース層(domain と infra を結合)
## テスト方針
- ユニットテストのカバレッジ80%以上
- API エンドポイントには統合テスト必須
- テストファイルは対象ファイルと同じディレクトリに配置
リンターとテストの自動フィードバックループ
AIエージェントの重要な特性は、エラーメッセージを読んで自己修正できることです。リンターやテストの出力をエージェントに返すことで、人間の介入なしに修正サイクルが回ります。
エージェントがコード生成
→ ESLintがエラー検出
→ エラーメッセージをエージェントに返却
→ エージェントが修正
→ 再度ESLint実行
→ パス → 次のステップへ
この「ループを閉じる」仕組みが、エージェンティックエンジニアリングの生産性の源泉です。エージェントが自律的にデバッグできる環境を構築することで、人間はより上位の判断に時間を使えます。
組織への影響と役割の変化
エンジニアの新しい価値
エージェンティックエンジニアリングの普及により、エンジニアに求められるスキルが変化します。
価値が上がるスキル:
- アーキテクチャ設計: システム全体の構造を決定する能力
- コンテキスト設計: AIが正しく動くための情報構造を設計する能力
- 出力評価: AIが生成したコードの品質・安全性を判断する能力
- ドメイン知識: ビジネス要件を技術要件に変換する能力
自動化されるスキル:
- 定型的なCRUD実装
- テストコードの生成
- リファクタリング(パターンの適用)
- ドキュメント・コメントの生成
ペアプログラミングの「ドライバーとナビゲーター」に例えると、AIエージェントがドライバー(コードを書く役割)を担い、人間がナビゲーター(方向性を決める役割)に専念する構図です。ナビゲーターはコードを書きませんが、プロジェクトの成功に対する責任を担います。
チーム構成への影響
海外のテック企業では、エージェンティックエンジニアリングの導入により「少人数で高い生産性を実現する」事例が報告されています。ある開発者は5日間で61コミット・507のテスト・12,000行のコードを含むシステムを本番デプロイした事例を公開しています。コードを一行も手書きしていないが、すべての設計判断は人間が行ったというケースです。
一方で「人間が不要になる」という極端な見方は現時点では妥当ではありません。AIが生成したコードの品質を担保するには、その技術領域を深く理解した人間のレビューが不可欠です。表面的なコーディングスキルだけを持つ「浅い専門化」の価値は下がりますが、アーキテクチャ・セキュリティ・分散システム・データモデリングなどの深い専門性はむしろ需要が高まります。
エージェンティックエンジニアリングの活用領域
ソフトウェア開発以外への拡張
エージェンティックエンジニアリングの概念は、コーディング以外の領域にも適用されています。
製造・シミュレーション領域: Rescale社はHPC(高性能コンピューティング)環境でのCAEシミュレーションワークフローを、AIエージェントで自動化するソリューションを提供しています。暗黙知に依存していた設計プロセスを、エージェントが再現可能な手順に変換します。
レガシーシステムのモダナイゼーション: 数十年分のレガシーコードを一度に書き換えるリスクを避けながら、エージェントが段階的にリファクタリング・テスト追加・ドキュメント化を行う「継続的モダナイゼーション」という活用パターンが海外で広まっています。大規模な書き換えプロジェクトの失敗リスクを軽減できるため、エンタープライズ領域での注目度が高まっています。
規制産業でのコンプライアンス管理: 医療・金融・インフラなどの規制が厳しい業界では、コーディング段階からコンプライアンス違反を自動検出するエージェントの活用が検討されています。リリース後の監査で問題を発見するのではなく、開発中に継続的にポリシー遵守を強制する仕組みです。
エージェンティックエンジニアリングを始めるためのツール
主要ツールの特徴
| ツール | 特徴 | エージェンティック機能 |
|---|---|---|
| Claude Code | CLIベースのAI開発ツール | サブエージェント起動、CLAUDE.mdによるコンテキスト管理、チーム機能 |
| Cursor | AI統合エディタ | エージェントモード、.cursorrules によるルール定義 |
| GitHub Copilot | GitHub統合のAIアシスタント | Copilot Workspace、エージェントモード |
| Zed | 高速エディタ | エージェンティックエンジニアリング専用機能を開発中 |
| Cline | VS Code拡張 | 自律的なコード変更、マルチステップタスク実行 |
ツール選定の指針
ツール選定では、AIモデルの性能よりも「ガードレールとの統合のしやすさ」を優先します。具体的には以下の基準で判断します。
- CLIとの親和性: パイプラインに組み込めるか
- コンテキストファイルのサポート: プロジェクト固有のルールを渡せるか
- テスト・リンターとの連携: 自動修正ループが構築できるか
- ブランチ戦略との統合: フィーチャーブランチ上での安全な作業が可能か
よくある誤解と注意点
「AIに任せれば品質が下がる」は半分正しい
ガードレールなしにAIエージェントに作業を任せれば、品質は確実に下がります。しかし適切な自動検証基盤を構築した上でエージェントを運用すれば、人間単独の開発よりも一貫性の高いコードが生成される場合もあります。品質の鍵はAIの能力ではなく、検証の仕組みにあります。
「基礎スキルが不要になる」は誤り
エージェンティックエンジニアリングはプログラミングの基礎知識を不要にしません。自分で理解していないコードのレビューはできません。AIが生成したコードにN+1クエリやメモリリークが含まれていることに気づくには、パフォーマンスチューニングの知識が必要です。エージェンティックエンジニアリングの恩恵は、基礎が固まったシニアエンジニアほど大きくなります。
「トークンコストを節約すべき」は逆効果
AIエージェントの使用量を絞ってコストを抑えようとするのは、多くの場合逆効果です。追加のトークンは「信頼性向上のためのコスト」と捉えるべきです。エージェントに自己修正ループを走らせる、並列でアプローチを検証する、テスト実行結果を返して修正させる。これらの工程がトークンを消費しますが、手戻りのコストに比べれば安価です。トークン単価はハードウェアコストと同様に継続的に下がる傾向にあるため、コスト節約よりも出力品質の最大化に投資する方が合理的です。
エージェンティックエンジニアリングの習得ロードマップ
フェーズ1: 基盤構築
- アーキテクチャ設計の基礎を固める(モジュール分割・責務分離・依存関係管理)
- テスト駆動開発(TDD)の実践
- CI/CDパイプラインの構築・運用経験
フェーズ2: AIツール活用
- Claude CodeやCursorなどのAIコーディングツールの習熟
- コンテキストファイル(CLAUDE.md等)の設計スキル
- プロンプトエンジニアリングの基礎(タスク分解・制約条件の明示)
フェーズ3: エージェント運用
- マルチエージェント構成の設計と実行
- ガードレール設計(リンター・テスト・フックの統合)
- エージェント出力のレビュースキル(セキュリティ・パフォーマンス観点)
フェーズ4: 組織展開
- チーム全体へのコンテキストファイル・ガードレールの展開
- エージェント活用のガイドライン策定
- 生産性メトリクスの設計と計測
まとめ
エージェンティックエンジニアリングは、AIをコード生成ツールとして使うバイブコーディングの次の段階に位置する開発手法です。複数のAIエージェントを統制し、ガードレールで品質を担保しながら、人間はアーキテクチャと設計判断に集中します。
始めるのに大規模な体制変更は不要です。まずは既存プロジェクトにコンテキストファイルを追加し、リンター・テスト・CIの自動検証基盤を整えるところから始められます。その上でエージェントへのタスク委任を段階的に拡大していけば、自然とエージェンティックエンジニアリングの実践に移行できます。
コードを書く能力ではなく、正しいコードかどうかを判断する能力。この「品質の審美眼」を持つエンジニアが、AI時代のソフトウェア開発を牽引していきます。