
PostgreSQLは長い歴史と高い信頼性を持つRDBMSですが、書き込みの水平スケーリングやゼロダウンタイムの障害復旧には構造的な制約があります。YugabyteDBは、こうしたPostgreSQLの限界を解消するために設計された分散SQLデータベースです。
YugabyteDBはGoogle Spannerのアーキテクチャに着想を得て開発され、PostgreSQLとの高い互換性を保ちながら、水平スケーリング・自動フェイルオーバー・地理分散を標準機能として提供します。ライセンスはApache 2.0で、コア機能は全て無償で利用できます。
YugabyteDBの概要と開発背景
YugabyteDBは、2016年に設立されたYugabyte Inc.(本社:米国カリフォルニア州サニーベール)が開発しています。創業者のKannan Muthukkaruppan、Karthik Ranganathan、Mikhail Bautinの3名は、いずれもFacebookでApache CassandraやApache HBaseなどの分散データベースの構築に携わった経験を持つエンジニアです。
2021年のシリーズCラウンドで1億8,800万ドルを調達し、評価額は13億ドルに達してユニコーン企業となりました。調達総額は累計2億9,100万ドルです(出典: Crunchbase)。GitHubでのスター数は10,100を超え、100か国以上で利用されています。
バージョンとリリースサイクル
YugabyteDBは年2回のメジャーリリースを行っており、YYYY.1がSTS(Standard-Term Support)、YYYY.2がLTS(Long-Term Support)として提供されます。
| リリース | バージョン | リリース日 | サポート期間 |
|---|---|---|---|
| 最新LTS | v2025.2.1.0 | 2026年2月 | 2年 + 延長180日 |
| 最新STS | v2025.1.3.2 | 2026年2月 | 1年 + 延長180日 |
| 前世代LTS | v2024.2系 | 2024年12月 | 2年 + 延長180日 |
v2025.1からPostgreSQLフォークがv11.2からv15.0にリベースされ、ストアド生成列・パーティションテーブルの外部キー・UNIQUE制約でのNon-Distinct NULLsなど、PG 15の主要機能に対応しました(出典: Yugabyte公式)。
アーキテクチャの仕組み
YugabyteDBのクラスターは、YB-MasterとYB-TServerという2つのコンポーネントで構成されます。
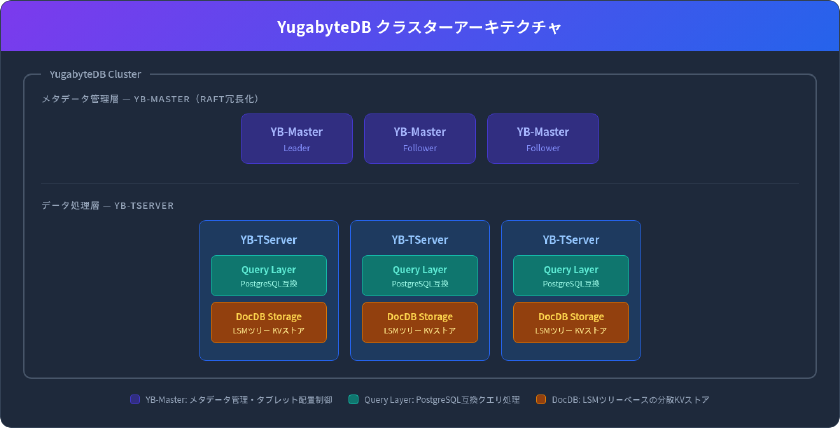
- YB-Master: クラスター全体のメタデータ管理、タブレットの配置制御、ノード参加・離脱の調整を担当します。Raftコンセンサスアルゴリズムで冗長化されています。
- YB-TServer: クライアントからのクエリ処理とデータ保持を担います。上位のクエリ層と下位のストレージ層(DocDB)に分かれています。
クエリ層とストレージ層
クエリ層はPostgreSQLのクエリ処理コードを再利用しており、これが高いSQL互換性の基盤です。v2025.1以降はPostgreSQL 15ベースとなり、サードパーティの互換性テストでは**85.08%**のスコアを記録しています(CockroachDBは53.66%)。
ストレージ層のDocDBは、LSMツリーベースのKVストアです。テーブルデータはtabletと呼ばれるシャードに自動分割され、各ノードに分散配置されます。同一データを持つ複数のtabletはtablet peerを構成し、Raftアルゴリズムで同期レプリケーションを行います。
シャーディング方式の選択
YugabyteDBはハッシュシャーディングとレンジシャーディングの2種類を提供しています。
| 方式 | 特徴 | 適するワークロード |
|---|---|---|
| ハッシュシャーディング | PKの先頭列をハッシュ化して均等分散 | ポイントルックアップ中心のOLTP |
| レンジシャーディング | PKの値域で分割 | 時系列データ、範囲スキャン |
デフォルトはハッシュシャーディングです。米国のベンチマーク(Sysbench)では、BETWEEN句を多用するワークロードでハッシュシャーディングを使用した場合にフルスキャンが発生し性能が大幅に低下する事例が報告されています。時系列データや範囲クエリが中心のアプリケーションでは、テーブル作成時にASC指定でレンジシャーディングを選択するのが重要です。
障害時の自動復旧
あるノードがダウンすると、YugabyteDBはRaftプロトコルにより3秒以内にfollower tabletをleaderに昇格させます。クライアント接続は透過的に新しいleaderへ切り替わるため、アプリケーション側でフェイルオーバー処理を実装する必要がありません。従来のPostgreSQLでは外部のクラスタリングソフトウェア(Pgpool-IIやPowerGres HAなど)が必要で、切り替え時に数秒〜数十秒のダウンタイムが発生しますが、YugabyteDBではビルトインでゼロダウンタイムが実現されます。
PostgreSQLユーザーが直面する課題とYugabyteDBでの解決
PostgreSQLで長年知られている構造的な課題に対して、YugabyteDBのアーキテクチャがどう対処しているかを整理します。
| PostgreSQLの課題 | 原因 | YugabyteDBでの対策 |
|---|---|---|
| XID周回問題 | 32ビットのトランザクションIDが約42億で周回 | ハイブリッド論理クロック(HLC)により周回が発生しない |
| VACUUMの負荷 | MVCCの不要タプルを定期的に回収する必要がある | LSMツリーのコンパクションで自動的にガベージ回収 |
| プロセス単位の接続モデル | 1接続=1プロセスで、同時接続数に限界がある | 組み込みコネクションマネージャーにより20倍高速な接続確立と5倍の同時接続をサポート |
| 書き込みのスケール不可 | プライマリ1台のみが書き込みを受け付ける | 全ノードが書き込みを受け付け、水平スケール可能 |
| メジャーバージョンアップ時のダウンタイム | pg_upgradeにDB停止が必要 | ローリングアップグレードで99.99%稼働率を維持 |
3つの対応API
YugabyteDBはPostgreSQL互換だけでなく、合計3つのAPIを提供しています。
- YSQL(PostgreSQL互換): ポート5433。psqlやJDBC/psycopg2でそのまま接続可能です。ストアドプロシージャ、トリガー、ビュー、CTEなどPostgreSQLの主要機能に対応しています。
- YCQL(Apache Cassandra互換): ポート9042。Cassandraのクエリ言語(CQL)互換APIです。Key-Value型のワークロードに適しています。
- MongoDB互換API(v2025.1以降): ドキュメント型のワークロードにも対応するAPIが追加されました。
1つのクラスターで複数のデータモデルに対応できるため、マイクロサービスアーキテクチャでサービスごとに異なるデータアクセスパターンを持つケースに向いています。
CockroachDB・TiDBとの比較
分散SQLデータベースを評価する際に、CockroachDBとTiDBはYugabyteDBと並ぶ有力な選択肢です。
| 項目 | YugabyteDB | CockroachDB | TiDB |
|---|---|---|---|
| SQL互換 | PostgreSQL (PG 15) | PostgreSQL (Wire互換) | MySQL |
| PostgreSQL互換度 | 85.08% | 53.66% | N/A(MySQL互換) |
| ストレージエンジン | DocDB(LSMツリー) | Pebble(LSMツリー) | TiKV(Raftベース) |
| ライセンス | Apache 2.0(全機能OSS) | BSL(商用制限あり) | Apache 2.0 |
| マルチAPI | PostgreSQL / Cassandra / MongoDB | PostgreSQLのみ | MySQLのみ |
| HTAP対応 | OLTP特化 | OLTP特化 | OLTP + OLAP(TiFlash) |
| 障害復旧時間 | 約3秒 | 数秒(公称) | 約30秒 |
| テスト済み最大ノード数 | 100ノード | 300ノード | 非公開 |
| マイグレーションツール | Voyager(Oracle/MySQL/PG対応) | AWS DMS依存 | TiDB Lightning / DM |
| マネージドサービス | Aeon(AWS/GCP/Azure) | CockroachDB Cloud | TiDB Cloud |
ライセンスの違い
ライセンス体系は選定における重要な判断基準です。YugabyteDBはApache 2.0ライセンスで、分散バックアップ・データ暗号化・読み取りレプリカなどのエンタープライズ級機能も含めて全てオープンソースで提供されています。
CockroachDBは2024年にBusiness Source License(BSL)へ変更し、年間売上1,000万ドルを超える企業はエンタープライズライセンスの購入が必要です。MongoDB(SSPL)と同様に、商用利用に制約がかかる構造です。
TiDBのコアはApache 2.0ですが、TiFlash(列指向ストア)など一部コンポーネントには別ライセンスが適用されます。
ベンチマーク上の特性
米国での各種ベンチマーク結果から見えてくる性能特性をまとめます。
- 書き込み性能: YugabyteDBが優位。Sysbenchの
oltp_update_non_indexテストで、YugabyteDBは約17,000〜19,000 QPSを記録したのに対し、TiDB For PostgreSQLは約415〜9,000 QPSにとどまりました。 - 範囲スキャン: TiDBが優位。ハッシュシャーディング使用時のYugabyteDBはBETWEEN句でフルスキャンが発生するため、レンジクエリ中心のワークロードでは注意が必要です。
- Aurora PostgreSQLとの比較: 100ノードクラスターで126万writes/secを記録。Auroraの書き込み上限(約16.8万ops/sec)を大幅に上回ります。ただしAuroraは単一ライターモデルのため分散トランザクションのオーバーヘッドがなく、小規模ワークロードではAuroraが有利です。
料金体系とデプロイ形態
YugabyteDBは、用途に応じた複数のデプロイ形態を提供しています。
無償版(コミュニティ版)
コアデータベース機能をApache 2.0ライセンスで利用できます。オンプレミス、クラウドVM、Docker、Kubernetesなど任意の環境にデプロイ可能です。
YugabyteDB Aeon(マネージドサービス)
旧称「YugabyteDB Managed」から改称された、フルマネージドのDBaaSです。
| プラン | 月額料金 | 対象 | レジリエンス |
|---|---|---|---|
| Sandbox | 無料(永続) | 評価・学習 | 1ノード、10GB |
| Standard | $125/vCPU | スタートアップ | AZレベル |
| Professional | $167/vCPU | グローバル展開 | リージョンレベル |
| Enterprise | 要問い合わせ | ミッションクリティカル | カスタム |
追加コストとして、ストレージ $0.10/GB/月、バックアップ $0.025/GB/月、リージョン間データ転送 $0.10/GBが発生します(出典: Yugabyte料金ページ)。
Professionalプランには、エンタープライズセキュリティ(SSO・暗号化キー管理・監査ログ)やDR機能をアドオン(各$25/vCPU/月)で追加できます。
Aeon BYOC(Bring Your Own Cloud)
自社のクラウドアカウント(AWS/GCP/Azure)上でYugabyteが運用管理を代行する形態です。データは自社のVPCから外に出ないため、金融機関やヘルスケア企業など、データ所在地に厳格な要件がある組織に適しています。
AWS Gravitonとのコスト最適化
YugabyteDB AeonはAWS Graviton(ARM)インスタンスに対応しており、x86ベースのEC2 M5インスタンスと比較して22%のコスト削減と最大65%の電力効率改善が見込めます。2024年11月時点で8,500以上のGravitonクラスターが稼働しています(出典: AWS Partner Blog)。
DockerとKubernetesでの導入手順
Docker Composeでの3ノードクラスター構築
開発・検証環境で最も手軽にYugabyteDBを試す方法はDockerです。以下のDocker Compose定義で3ノードクラスターを起動できます。
# docker-compose.yml
version: "3"
services:
yugabyte-node1:
image: yugabytedb/yugabyte:2025.2.1.0-b141
container_name: yb-node1
command: >
bin/yugabyted start
--advertise_address=yugabyte-node1
--cloud_location=cloud.region.zone1
--fault_tolerance=zone
--daemon=false
ports:
- "5433:5433" # YSQL
- "9042:9042" # YCQL
- "15433:15433" # 管理UI
- "7000:7000" # Master UI
volumes:
- yb-data1:/home/yugabyte/var
yugabyte-node2:
image: yugabytedb/yugabyte:2025.2.1.0-b141
container_name: yb-node2
command: >
bin/yugabyted start
--advertise_address=yugabyte-node2
--join=yugabyte-node1
--cloud_location=cloud.region.zone2
--fault_tolerance=zone
--daemon=false
depends_on:
- yugabyte-node1
volumes:
- yb-data2:/home/yugabyte/var
yugabyte-node3:
image: yugabytedb/yugabyte:2025.2.1.0-b141
container_name: yb-node3
command: >
bin/yugabyted start
--advertise_address=yugabyte-node3
--join=yugabyte-node1
--cloud_location=cloud.region.zone3
--fault_tolerance=zone
--daemon=false
depends_on:
- yugabyte-node1
volumes:
- yb-data3:/home/yugabyte/var
volumes:
yb-data1:
yb-data2:
yb-data3:
起動後、PostgreSQLと同じpsqlコマンドで接続できます。
docker compose up -d
# YSQL接続(PostgreSQL互換)
psql -h localhost -p 5433 -U yugabyte
# 管理UIへアクセス
# http://localhost:15433
colocatedオプションを使うと、小規模なルックアップテーブルを1つのtabletにまとめてJOINのオーバーヘッドを削減できます。
CREATE DATABASE app_db WITH COLOCATION = true;
Kubernetesでのデプロイ
公式のHelm Chartが提供されています。
helm repo add yugabytedb https://charts.yugabyte.com
helm repo update
helm install yb-cluster yugabytedb/yugabyte \
--set resource.tserver.requests.cpu=2 \
--set resource.tserver.requests.memory=4Gi \
--set replicas.tserver=3 \
--set replicas.master=3
Kubernetes Operatorも用意されており、StatefulSetベースの自動スケーリング、ローリングアップグレード、バックアップ・リストアの自動化に対応しています。
PostgreSQLからの移行パス
YugabyteDB Voyager
YugabyteDB Voyagerは、既存データベースからYugabyteDBへの移行を支援する専用ツールです。
対応するソースデータベースは以下の通りです。
- PostgreSQL
- Oracle
- MySQL
Voyagerは、スキーマ変換・データ移行・ライブレプリケーションの3フェーズで移行を実行します。ライブマイグレーションモードでは、fall-forward(移行先へのフェイルオーバー)とfall-back(移行元への切り戻し)の両方に対応しており、万が一移行後に問題が発生した場合も元のデータベースに戻せます。
CockroachDBのマイグレーションがAWS DMSに依存しているのに対して、Voyagerはクラウドに依存せず、オンプレミス環境でも利用できます。
互換性の実態
PostgreSQLからの移行において、アプリケーション側の修正は最小限で済みます。接続先のポート番号を5432から5433に変更するだけで、psqlやpsycopg2、JDBC(pgドライバー)経由のアクセスがそのまま動作します。
ただし、YugabyteDB固有の考慮事項もあります。
- テンポラリテーブル: 一部制約あり(分散環境での一時テーブルは単一ノードに配置)
- GINインデックス: v2025.2時点で部分的サポート
- カスタムC拡張: PostgreSQLのC言語拡張は再コンパイルが必要な場合があります
移行前の互換性評価には、Voyagerのアセスメント機能で未対応のSQL構文やデータ型を事前に検出できます。
AI・生成AIアプリケーションとの統合
YugabyteDBは、pgvector拡張によるベクター類似検索を分散環境で利用できます。
pgvectorによるベクター検索
-- pgvector拡張のインストール
CREATE EXTENSION vector;
-- ベクター列を含むテーブル作成
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536)
);
-- HNSWインデックスの作成
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
-- コサイン類似度による検索
SELECT id, content
FROM documents
ORDER BY embedding <=> '[0.1, 0.2, ...]'::vector
LIMIT 10;
ベクターインデックスはtablet間で分散配置されるため、数億件規模のベクターデータでも水平スケーリングによる検索性能の維持が期待できます。単一ノードのPostgreSQL + pgvectorでは対応しきれない規模のRAGアプリケーションに適しています。
LLMフレームワーク統合
v2025.1以降、以下のAI/MLフレームワークとの統合が公式にサポートされています。
- LangChain: ベクターストアとしてYugabyteDBを直接利用可能
- LlamaIndex: ドキュメントインデックスのバックエンドとして対応
- AWS Bedrock / Google Vertex AI: エンベディング生成と連携
- Ollama: ローカルLLM環境との統合
また、YugabyteDB MCP Serverが提供されており、AIエージェントがYugabyteDBに直接クエリを発行するModel Context Protocol(MCP)ベースの統合も可能です。
国内外の導入事例
グローバル事例
| 企業 | 業界 | 活用内容 |
|---|---|---|
| Kroger(米国大手スーパー) | 小売 | 5,000コア以上の本番環境、10ms未満のレイテンシ |
| Temenos(銀行向けSaaS) | 金融 | AWS上で10万トランザクション/秒を達成 |
| Fiserv | 決済 | コア決済アプリのモダナイゼーション |
| Plume | IoT | 日次270億オペレーションのスマートホーム基盤 |
NFLスーパーボウルの配信プラットフォームにもYugabyteDBが採用され、ピークトラフィック時の安定稼働を実現しました(出典: AWS Partner Blog)。
業界別ユースケース
YugabyteDBが効果を発揮する代表的なシナリオは以下の通りです。
- 金融・決済: マイクロペイメント基盤でのACIDトランザクション + 水平スケール。リージョン障害時もデータ損失なく継続稼働
- 通信・IoT: 大量のセンサーデータ書き込みを複数ノードで分散処理。国内ではある通信企業が150万台のIoTデバイスの接続基盤として利用
- EC・リテール: フラッシュセールやキャンペーンによるスパイクアクセスに対して、ノード追加でリアルタイムにスケールアウト
- ゲーム・動画配信: ユーザー行動に連動する負荷変動に対応。地理分散配置でユーザーに近いリージョンからの低レイテンシ応答を実現
データ分散と地理分散の設計パターン
YugabyteDBは、用途に応じた複数の分散パターンを提供しています。
| パターン | レプリケーション | 用途 | 書き込みレイテンシ |
|---|---|---|---|
| デフォルト(同一リージョン) | 同期 | 一般的なOLTP | 低(同一AZ内) |
| Geo-partitioning | 同期 | データ主権要件、GDPR対応 | 低(ローカルリード) |
| xCluster | 非同期(単方向/双方向) | マルチクラスターDR | 低(ローカル書き込み) |
| Read Replica | 非同期 | 読み取り負荷分散 | 低(レプリカからの読み取り) |
Geo-partitioningでは、行レベルでデータの配置リージョンを指定できます。たとえば日本のユーザーデータを東京リージョン、米国のユーザーデータをバージニアリージョンに配置し、各地域のユーザーが最寄りのノードからデータを読み書きする構成が可能です。
xCluster Replicationは、v2025.2でYSQL DDL変更の自動レプリケーションに対応しました。従来はDDL変更を両クラスターに手動で適用する必要がありましたが、自動モードにより運用負荷が大幅に軽減されています。
プログラミング言語からの接続
PostgreSQL互換のため、既存のPostgreSQLドライバーやORMがそのまま利用できます。
Pythonからの接続例
import psycopg2
conn = psycopg2.connect(
host="localhost",
port=5433,
dbname="yugabyte",
user="yugabyte",
password="yugabyte"
)
cur = conn.cursor()
cur.execute("SELECT * FROM yb_servers()")
for row in cur.fetchall():
print(row)
conn.close()
Yugabyte専用ドライバーpsycopg2-yugabytedbを使用すると、クラスターのトポロジーを自動検出してノード間でロードバランシングを行い、外部ロードバランサーが不要になります。
対応言語とドライバー
| 言語 | 標準ドライバー | Yugabyte拡張ドライバー |
|---|---|---|
| Python | psycopg2 | psycopg2-yugabytedb |
| Java | PostgreSQL JDBC | YugabyteDB JDBC(トポロジー対応) |
| Node.js | pg | pg(そのまま利用可能) |
| Go | pgx, lib/pq | そのまま利用可能 |
| Rust | tokio-postgres, diesel | そのまま利用可能(Dieselでの接続実績あり) |
| C# / .NET | Npgsql | そのまま利用可能 |
まとめ
YugabyteDBは、PostgreSQL 15互換の分散SQLデータベースとして、水平スケーリング・自動障害復旧・地理分散をビルトインで提供します。Apache 2.0ライセンスでエンタープライズ機能を含む全コードが公開されており、CockroachDB(BSL制限あり)やTiDB(MySQL互換)との差別化ポイントも明確です。
v2025.1以降はpgvectorによるベクター検索やMCP Serverなど、AI/GenAI領域への対応も強化されています。PostgreSQLの書き込みスケーリングやダウンタイムに課題を抱えている環境、または分散SQLデータベースの導入を検討している段階であれば、Dockerでの検証環境構築から試してみる価値があります。
日本国内では、SRA OSS(公式技術ブログ)やULSコンサルティング(YugabyteDBサービスページ)がコンサルティング・導入支援サービスを提供しています。