
大規模データを低レイテンシで読み書きしたい——そのニーズに応えるために設計されたのがApache HBase(エイチベース)です。Google Bigtableの論文をもとに開発されたオープンソースの分散NoSQLデータベースで、HDFS(Hadoop Distributed File System)上に構築されます。数十億行×数百万列のテーブルを数百ノードに分散しながら、ミリ秒単位のランダムアクセスを実現する点が最大の強みです。
ここではHBaseのアーキテクチャからデータモデル、他のNoSQLとの使い分け、実際の導入事例、そして2026年時点でのプロジェクト状況までを体系的に整理しています。
HBaseの定義と名前の由来
Apache HBase(読み方:エイチベース)は、Apache Software Foundationが開発・公開している列指向(ワイドカラムストア型)の分散NoSQLデータベース管理システムです。Javaで実装されており、Hadoop Distributed File System(HDFS)をストレージ層として利用します。
名前の「HBase」は「Hadoop Database」に由来します。Googleが2006年に発表した論文「Bigtable: A Distributed Storage System for Structured Data」(出典: Google Research)のオープンソース実装として位置づけられており、公式サイトでも「Bigtable-like capabilities on top of Hadoop and HDFS」と説明されています(出典: Apache HBase)。
RDBのようなスキーマ定義やSQL、トランザクション制御を備えていない代わりに、水平スケーリングと大量データへの高速ランダムアクセスに特化した設計になっています。
開発の歴史 — Powersetから Apache トップレベルプロジェクトへ
HBaseの開発は2006年、自然言語検索エンジンを開発していた米国企業 Powersetで始まりました。Webの膨大なテキストデータを処理するために、Bigtableの設計思想をオープンソースで再現するプロジェクトとしてChad WaltersとJim Kellermanが開発に着手しています(出典: Apache Software Foundation)。
主要なマイルストーンは次のとおりです。
| 年 | 出来事 |
|---|---|
| 2006年 | Bigtable論文発表。Powersetで開発開始 |
| 2007年 | Apache Hadoopのサブプロジェクトとして組み込み |
| 2008年 | Microsoftによるpowerset買収後も開発継続 |
| 2010年5月 | **Apacheトップレベルプロジェクト(TLP)**に昇格 |
| 2010年11月 | FacebookがFacebook MessagesのバックエンドにHBaseを採用 |
| 2025年11月 | 安定版 2.5.13 / 2.6.4 リリース |
Apacheトップレベルプロジェクトへの昇格は2010年5月4日にASFから正式発表されました(出典: ASF)。
アーキテクチャ — HBaseの内部構造
HBaseのクラスタは3種類のプロセスで構成されます。
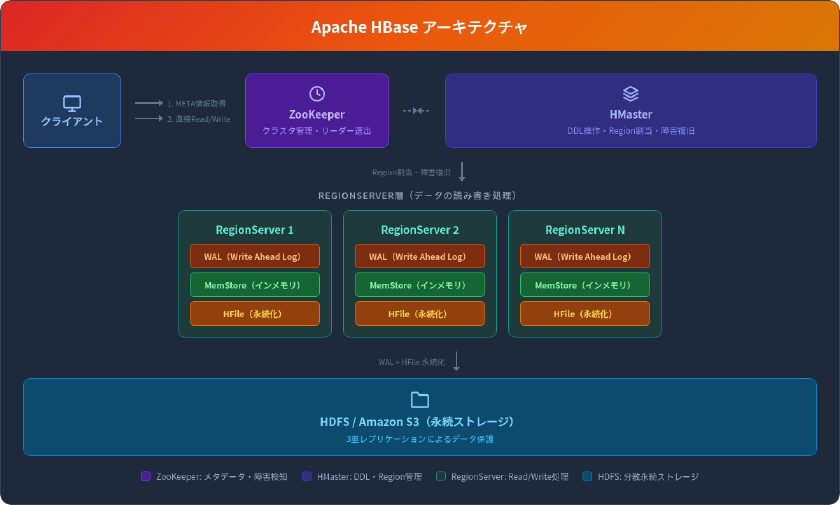
HMaster
テーブルの作成・削除(DDL操作)やRegionの割り当て・負荷分散を担当します。ただし、データの読み書き自体にはHMasterは関与しません。クライアントはHMasterを経由せずRegionServerと直接通信するため、HMasterがボトルネックになりにくい設計です。
RegionServer
テーブルデータを「Region」という単位で分割して保持し、クライアントからのGet/Put/Scan/Delete操作を処理します。各Regionはデフォルトで約10GBに達すると自動的に分割(auto-split)されます。
書き込み処理の内部フローは次のとおりです。
- WAL(Write Ahead Log) に書き込み内容をHDFS上のHLogに記録
- MemStore(インメモリバッファ)にデータを保存
- MemStoreが一定サイズに達するとHFileとしてHDFSにフラッシュ
- RegionServer障害時はWALから別のRegionServerがリプレイして復旧
読み取り処理では、クライアントはまずZooKeeperからMETAテーブルの所在を取得し、METAから対象データのRegionServer位置を特定して、直接RegionServerにアクセスします。この位置情報はクライアント側にキャッシュされるため、2回目以降のアクセスはさらに高速です。
ZooKeeper
クラスタのメタデータ管理、HMasterのリーダー選出、RegionServerの障害検知を行います。
列指向データモデル — RDBとの違い
HBaseのデータ構造はRDBとは根本的に異なります。RDBが行単位で固定スキーマのテーブルを扱うのに対し、HBaseは行キー・カラムファミリ・カラム修飾子・タイムスタンプの4次元でデータを管理します。
| 要素 | 説明 |
|---|---|
| 行キー(Row Key) | 各行の一意識別子。辞書順にソートされて格納される |
| カラムファミリ | カラムのグループ。テーブル作成時に定義が必要 |
| カラム修飾子 | カラムファミリ内の個別カラム。スキーマ定義不要で自由に追加可能 |
| セル | 行キー+カラムで特定される値。タイムスタンプ付きで複数バージョンを保持 |
RDBとの主な違いをまとめます。
| 比較項目 | RDB(MySQL等) | HBase |
|---|---|---|
| スキーマ | 固定。事前にCREATE TABLE | カラムファミリのみ事前定義。カラムは動的追加 |
| データ型 | INTEGER, VARCHAR等 | すべてバイト配列 |
| SQL | ネイティブサポート | 非対応(Apache Phoenix経由で利用可) |
| トランザクション | ACID対応 | 行レベルのアトミック操作のみ |
| インデックス | 複合インデックス対応 | 行キーのみ(セカンダリはPhoenix等で追加) |
| バージョニング | 通常なし | セル単位でタイムスタンプ付き複数バージョン保持 |
| スケーリング | 垂直スケールが中心 | 水平スケールが前提 |
セル単位でタイムスタンプ付きの複数バージョンを保持できる点は、データの変更履歴が重要な時系列分析やログ管理で特に有用です。
HBaseが選ばれる5つの技術的理由
1. 水平スケーラビリティ
ノードを追加するだけでストレージと処理能力を拡張できます。Regionが自動分割・再配置されるため、テーブルサイズの増加に対してリニアに性能をスケールさせることが可能です。数千台のサーバーでペタバイト規模のデータを扱った実績があります。
2. ミリ秒単位のランダムアクセス
数十億行規模のテーブルに対しても、行キー指定のGet操作はミリ秒オーダーで完了します。MemStoreとBlockCacheによるインメモリ層とカラムファミリ単位のBloomフィルタ(Bigtable論文由来)が、不要なディスクI/Oを排除しています。
3. 強整合性(CAP定理でCP型)
分散システムの設計指針であるCAP定理の分類において、HBaseはCP型(一貫性+分断耐性)に該当します。書き込みが完了した時点で、どのRegionServerから読み取っても最新データが返される強整合性(Strong Consistency)を保証します。
結果整合性(Eventual Consistency)モデルのCassandraとはこの点が大きく異なり、金融取引やメッセージングなど最新データの正確性が必須な場面ではHBaseの強整合性が優位に立ちます。
4. フォールトトレランス
HDFSのデフォルト3重レプリケーションとWAL(Write Ahead Log)により、ノード障害時のデータ損失を防ぎます。RegionServerがダウンするとZooKeeperがこれを検知し、HMasterが別のサーバーにRegionを再割当て、WALからデータをリプレイして復旧します。
5. Hadoopエコシステムとの統合
MapReduce、Apache Hive、Apache Spark、Apache Pigなどとネイティブに連携できます。HBaseに蓄積したリアルタイムデータをSparkでバッチ分析する、HiveからSQLでクエリする、といったユースケースが1つのクラスタ上で実現します。
NoSQLの中でのHBaseの位置づけ
NoSQLデータベースは用途やデータモデルによっていくつかの類型に分かれます。HBaseはワイドカラムストアに分類されます。
| 分類 | 代表的な製品 | データ構造 | 主な用途 |
|---|---|---|---|
| キーバリュー型 | Redis, Amazon DynamoDB | キーと値のペア | キャッシュ、セッション管理 |
| ドキュメント型 | MongoDB, Couchbase | JSON/BSONドキュメント | CMS、ユーザープロフィール |
| ワイドカラム型 | HBase, Cassandra, ScyllaDB | 行キー+カラムファミリ | 時系列データ、IoT、ログ |
| グラフ型 | Neo4j, Amazon Neptune | ノードとエッジ | SNS関係性、推薦エンジン |
HBaseとCassandraの違い
同じワイドカラムストアでも、HBaseとApache Cassandraは設計思想が異なります。
| 比較項目 | HBase | Cassandra |
|---|---|---|
| 整合性モデル | 強整合性(CP型) | 結果整合性(AP型)※調整可能 |
| マスター構成 | HMaster+RegionServer(マスター・スレーブ型) | マスターなし(ピアツーピア型) |
| ストレージ | HDFS依存 | 独自ストレージエンジン |
| 書き込み性能 | 高い(ただしHDFS依存) | 非常に高い(同時書き込み対応) |
| Hadoop連携 | ネイティブ | 連携可能だが追加設定が必要 |
| 運用複雑度 | Hadoop/HDFS/ZooKeeperの管理が必要 | 単体で動作し運用がシンプル |
| 適したケース | Hadoop基盤がある環境での読み書き混在 | 書き込みヘビーなグローバル分散 |
Hadoopエコシステムをすでに運用している環境ではHBase、Hadoop基盤がなく単体で使いたい場合やマルチデータセンター構成ではCassandraが有力な選択肢になります。
HBaseが適した場面と不向きなケース
適した場面
- 時系列データの蓄積と検索 — IoTセンサーデータ、金融取引ログ、サーバーメトリクスなど、タイムスタンプ付きデータの大量書き込みと範囲検索
- メッセージングプラットフォーム — チャット履歴のような大規模データへのリアルタイムアクセス
- 広告・レコメンデーション — ユーザー行動ログの蓄積と低レイテンシ参照
- ゲノム解析・科学データ — 遺伝子配列のような大規模疎行列データの格納
- スポーツ分析・不正検知 — 米国ではスポーツの対戦履歴分析や文書指紋(盗用検出)のストレージとしての利用例も報告されています
不向きなケース
HBaseは万能ではなく、以下のケースには向いていません。
| 条件 | 推奨される代替 |
|---|---|
| 数百万行以下の中小規模データ | RDB(PostgreSQL, MySQL) |
| 複雑なJOINやトランザクションが必要 | RDB |
| Hadoop基盤がなく単体でNoSQLを使いたい | Cassandra, MongoDB, Redis |
| SQLによるアドホッククエリが中心 | RDBまたはApache Hive |
| グラフ構造の関係性データ | Neo4j, Amazon Neptune |
重要な点として、HBaseにはRDBにあるカラム型制約、複合インデックス、トリガー、ネイティブSQLサポートがありません。Apache Phoenixを導入すればJDBC経由でSQLを発行できますが、RDBと同等の機能を期待するとギャップが生じます。Hadoop基盤への投資がない環境であれば、Cassandra・MongoDB・Redisなど単体で完結するNoSQLのほうが導入ハードルは低くなります。
導入企業の事例
Facebook — 大規模採用と次世代への移行
2010年11月、FacebookはFacebook MessagesのバックエンドとしてHBaseを採用しました。当時の選定理由として、同社エンジニアのKannan Muthukkaruppan氏は「MySQLはロングテールデータの扱いに限界があり、CassandraのEventual Consistencyモデルは新たなメッセージング基盤に組み込むことが難しかった」と公表しています(出典: Engineering at Meta)。
月間3億5,000万人が交わす150億件ものメッセージをHBaseの強整合性とスケーラビリティで支えました。その後、2014年にはHydraBase(マルチリージョン対応版)へ進化し、2018年にはMyRocks(MySQL+RocksDBストレージエンジン)へ移行しています。採用から移行までの全ライフサイクルは、HBaseの強みと限界の両面を示す貴重なケースです。
Adobe — 初期からの本番運用
Adobe社は2008年10月からHBaseを本番環境で稼働させており、公式の「Powered by HBase」ページにも掲載されています。HDFSノード30台規模のクラスタを運用し、社内の構造化データと外部から取得する非構造化データの双方をHBaseで一元管理していました(出典: Apache HBase Powered By)。
LINE — メッセージ基盤での活用
LINE株式会社はメッセージングプラットフォームのストレージ基盤としてHBaseを活用しています。LINE DEVELOPER DAY 2017での発表によると、1日あたり数百億行のメッセージデータをサブ10ミリ秒のレスポンスで処理するデュアルクラスタ構成を運用しています(出典: SlideShare - HBase at LINE 2017)。
FINRA — 3兆レコードの金融規制データ
米国金融業規制機構(FINRA)は、証券取引の監視システムにHBaseを採用しています。AWSの事例として公開されており、3兆件超のレコードを格納し、1日あたり数十億件のペースで増加するデータを処理しています。ストレージをHDFSからAmazon S3に切り替えたことで、年間60%以上のコスト削減とクラスタ復旧時間の大幅短縮(数日→30分未満)を実現しました(出典: AWS)。
その他の採用企業
Apache HBaseの公式ページやWikipediaには、以下の企業・サービスも採用実績として記録されています。
- Airbnb — リアルタイムストリーム処理基盤(AirStream)の一部
- Bloomberg — 時系列データストレージ
- Spotify — 機械学習パイプラインの基盤データストア
- Pinterest, Netflix, Salesforce, Twitter — 大規模データ処理基盤
(出典: Apache HBase - Powered By, Wikipedia - Apache HBase)
2026年のHBase — プロジェクトの現在地
「Hadoopは終わった」という声がエンジニアコミュニティで聞かれることがありますが、HBase自体は2026年時点でもアクティブに開発が続いています。
リリース状況
2025年11月14日に安定版2.5.13と最新機能版2.6.4が同日リリースされました。2.6系ではTLS対応などセキュリティ面の強化が進んでいます。次期メジャーバージョンである3.0.0はベータ段階(3.0.0-beta-1、2024年1月リリース)で、安定版リリースに向けた開発が進行中です(出典: Apache HBase Downloads)。
コミュニティの活性度
GitHubリポジトリの統計は、プロジェクトの健全性を示しています。
| 指標 | 数値 |
|---|---|
| GitHub Stars | 5,600以上 |
| コントリビュータ数 | 501人 |
| コミッター数 | 107人 |
| 累計コミット | 20,900以上 |
クラウドマネージドサービスの選択肢
自前でHadoop/HBaseクラスタを構築・運用するコストを避けたい場合、クラウドマネージドサービスが選択肢になります。
| サービス | 提供元 | 特徴 |
|---|---|---|
| Google Cloud Bigtable | Google Cloud | Bigtableの設計を継承したフルマネージドサービス。HBase互換のJava APIを提供 |
| Amazon EMR(HBase) | AWS | EMRクラスタ上でHBaseを実行。S3をストレージに利用可能でコスト効率が高い |
| Azure HDInsight 5.1 | Microsoft Azure | HDInsight上でHBaseを実行。ただし旧版4.0は2025年3月に退役済み |
特にAWS EMRではストレージをHDFSからAmazon S3に切り替える構成が可能で、コンピュートとストレージを分離することでコスト最適化が実現します。前述のFINRA事例はこのパターンの代表例です。
HBaseの基本操作 — HBase Shellの例
HBaseには対話型シェル(HBase Shell)が付属しており、テーブル操作やデータの読み書きを行えます。
# テーブル作成(カラムファミリ 'cf' を定義)
create 'user_events', 'cf'
# データ書き込み(行キー 'user001', カラム 'cf:action', 値 'login')
put 'user_events', 'user001', 'cf:action', 'login'
put 'user_events', 'user001', 'cf:timestamp', '2026-03-03T10:00:00'
# データ読み取り
get 'user_events', 'user001'
# テーブル全体のスキャン
scan 'user_events'
# テーブル無効化と削除
disable 'user_events'
drop 'user_events'
SQLを使いたい場合はApache Phoenixを導入することで、JDBC経由でSQLクエリを発行できます。BIツールとの接続やアドホック分析が必要な場面ではPhoenixの併用が実用的です。
まとめ — HBase導入判断のポイント
Apache HBaseは、Hadoopエコシステム上で大量データへのリアルタイムランダムアクセスを実現する列指向NoSQLデータベースです。
導入を検討する際の判断ポイントを整理します。
- HBaseが最適 — 既存のHadoop/HDFS基盤がある、数十億〜数兆行規模のデータを扱う、強整合性が必要、時系列・IoT・メッセージングのワークロード
- 別の選択肢が有力 — Hadoop基盤がない(→ Cassandra, MongoDB)、数百万行以下の規模(→ PostgreSQL, MySQL)、複雑なJOINが必要(→ RDB)
2026年現在、HBaseは安定版のリリースが継続しており、クラウドマネージドサービス(Google Cloud Bigtable, Amazon EMR)を活用すれば運用負荷を抑えた導入も現実的です。データ基盤の技術選定において、強整合性を備えた大規模分散データベースとしてHBaseは引き続き有力な選択肢となっています。